| ▲ | Measuring Claude 4.7's tokenizer costs(claudecodecamp.com) |
| 488 points by aray07 7 hours ago | 231 comments |
| |
|
| ▲ | louiereederson 6 hours ago | parent | next [-] |
| LLMs exist on a logaritmhic performance/cost frontier. It's not really clear whether Opus 4.5+ represent a level shift on this frontier or just inhabits place on that curve which delivers higher performance, but at rapidly diminishing returns to inference cost. To me, it is hard to reject this hypothesis today. The fact that Anthropic is rapidly trying to increase price may betray the fact that their recent lead is at the cost of dramatically higher operating costs. Their gross margins in this past quarter will be an important data point on this. I think the tendency for graphs of model assessment to display the log of cost/tokens on the x axis (i.e. Artificial Analysis' site) has obscured this dynamic. |
| |
| ▲ | louiereederson 6 hours ago | parent | next [-] | | I meant reference Toby Ord's work here. I think his framing of the performance/cost frontier hasn't gotten enough attention https://www.tobyord.com/writing/hourly-costs-for-ai-agents | | |
| ▲ | dang 42 minutes ago | parent | next [-] | | Let's give that one a SCP* re-up: https://news.ycombinator.com/item?id=47778922 (* explained at https://news.ycombinator.com/item?id=26998308) | |
| ▲ | fragmede 3 hours ago | parent | prev [-] | | That post doesn't address the human factor of cost, and I don't mean that in a good way. Even if AI costs more than a human, it's tireless, doesn't need holidays, is never going to have to go to HR for sexual harassment issues, won't show up hungover or need an advance to pay for a dying relative's surgery. It can be turned on and off with the flip of a switch. Hire 30 today, fire 25 of them next week. Spin another 5 up just before the trade show demo needs to go out and fire them with no remorse afterwards. |
| |
| ▲ | Aurornis 4 hours ago | parent | prev | next [-] | | > It's not really clear whether Opus 4.5+ represent a level shift on this frontier or just inhabits place on that curve which delivers higher performance, but at rapidly diminishing returns to inference cost. I think we're reaching the point where more developers need to start right-sizing the model and effort level to the task. It was easy to get comfortable with using the best model at the highest setting for everything for a while, but as the models continue to scale and reasoning token budgets grow, that's no longer a safe default unless you have unlimited budgets. I welcome the idea of having multiple points on this curve that I can choose from. depending on the task. I'd welcome an option to have an even larger model that I could pull out for complex and important tasks, even if I had to let it run for 60 minutes in the background and made my entire 5-hour token quota disappear in one question. I know not everyone wants this mental overhead, though. I predict we'll see more attempts at smart routing to different models depending on the task, along with the predictable complaints from everyone when the results are less than predictable. | | |
| ▲ | KronisLV 2 hours ago | parent | next [-] | | > It was easy to get comfortable with using the best model at the highest setting for everything for a while, but as the models continue to scale and reasoning token budgets grow, that's no longer a safe default unless you have unlimited budgets. For a while I used Cerebras Code for 50 USD a month with them running a GLM model and giving you millions of tokens per day. It did a lot of heavy lifting in a software migration I was doing at the time (and made it DOABLE in the first place), BUT there were about 10 different places where the migration got fucked up and had to manually be fixed - files left over after refactoring (what's worse, duplicated ones basically), some constants and routes that are dead code, some development pages that weren't removed when they were superseded by others and so on. I would say that Claude Code with throwing Opus at most problems (and it using Sonnet or Haiku for sub-agents for simple and well specified tasks) is actually way better, simply because it fucks things up less often and review iterations at least catch when things are going wrong like that. Worse models (and pretty much every one that I can afford to launch locally, even ones that need around ~80 GB of VRAM in the context of an org wanting to self-host stuff) will be confidently wrong and place time bombs in your codebases that you won't even be aware of if you don't pay enough attention to everything - even when the task was rote bullshit that any model worth its salt should have resolved with 0 issues. My fear is that models that would let me truly be as productive as I want with any degree of confidence might be Mythos tier and the economics of that just wouldn't work out. | |
| ▲ | richstokes an hour ago | parent | prev | next [-] | | The problem is half the time you don't know you need the better model until the lesser model has made a massive mess. Then you have to do it again on the good model, wasting money. The "auto" modes don't seem to do a good job at picking a model IME. | |
| ▲ | dustingetz 3 hours ago | parent | prev | next [-] | | Human dev labor cost is still the high pole in the tent, even multiplying today's subsidized subscription cost by 10x. If the capability improvement trajectory continues, developers should prepare for a new economy where more productivity is achieved by fewer devs by shifting substantial labor budget to AI. | |
| ▲ | dahart 2 hours ago | parent | prev | next [-] | | > I know not everyone wants this mental overhead, though. I’m curious how to even do it. I have no idea how to choose which model to use in advance of a given task, regardless of the mental overhead. And unless you can predict perfectly what you need, there’s going to be some overuse due to choosing the wrong model and having to redo some work with a better model, I assume? | |
| ▲ | Leynos 3 hours ago | parent | prev | next [-] | | Isn't that essentially GPT Pro Extended Thinking? | |
| ▲ | jpalawaga 3 hours ago | parent | prev [-] | | Except developers can’t even do that. Estimation of any not-small task that hasn’t been done before is essentially a random guess. |
| |
| ▲ | snek_case 6 hours ago | parent | prev | next [-] | | They're also getting closer to IPO and have a growing user base. They can't justify losing a very large number of billions of other people's money in their IPO prospectus. So there's a push for them to increase revenue per user, which brings us closer to the real cost of running these models. | | |
| ▲ | giwook 6 hours ago | parent | next [-] | | I agree, and I'm also quite skeptical that Anthropic will be able to remain true to its initial, noble mission statement of acting for the global good once they IPO. At that point you are beholden to your shareholders and no longer can eschew profit in favor of ethics. Unfortunately, I think this is the beginning of the end of Anthropic and Modei being a company and CEO you could actually get behind and believe that they were trying to do "the right thing". It will become an increasingly more cutthroat competition between Anthropic and OpenAI (and perhaps Google eventually if they can close the gap between their frontier models and Claude/GPT) to win market share and revenue. Perhaps Amodei will eventually leave Anthropic too and start yet another AI startup because of Anthropic's seemingly inevitable prioritization of profit over safety. | |
| ▲ | ljm 4 hours ago | parent | prev | next [-] | | They're also getting into cloud compute given you can use the desktop app to work in a temporary sandbox that they provision for you. I was about to call it reselling but so many startups with their fingers in the tech startup pie offer containerised cloud compute akin to a loss leader. Harking back to the old days of buying clock time on a mainframe except you're getting it for free for a while. | |
| ▲ | zozbot234 4 hours ago | parent | prev [-] | | The "real cost" of running near-SOTA models is not a secret: you can run local models on your own infrastructure. When you do, you quickly find out that typical agentic coding incurs outsized costs by literal orders of magnitude compared to the simple Q&A chat most people use AI for. All tokens are very much not created equal, and the typical coding token (large model, large noisy context) costs a lot even under best-case caching scenarios. |
| |
| ▲ | amelius 17 minutes ago | parent | prev | next [-] | | Once they implement their models directly in silicon, the cost will come down and the speed will go up. See Taalas. | |
| ▲ | iainmerrick an hour ago | parent | prev | next [-] | | That sounds very plausible. But it implies they could offer even higher performance models at much higher costs if they chose to; and presumably they would if there were customers willing to pay. Is that the case? Surely there are a decent number of customers who’d be willing to pay more, much more, to get the very best LLMs possible. Like, Apple computers are already quite pricey -- $1000 or $2000 or so for a decent one. But you can spec up one that’s a bit better (not really that much better) and they’ll charge you $10K, $20K, $30K. Some customers want that and many are willing to pay for it. Is there an equivalent ultra-high-end LLM you can have if you’re willing to pay? Or does it not exist because it would cost too much to train? | | |
| ▲ | criemen an hour ago | parent [-] | | > Is there an equivalent ultra-high-end LLM you can have if you’re willing to pay? Or does it not exist because it would cost too much to train? I guess at the time that was GPT-4.5. I don't think people used it a lot because it was crazy expensive, and not that much better than the rest of the crop. |
| |
| ▲ | conductr an hour ago | parent | prev | next [-] | | Yeah. Combine this with much of Corpos right now using a “burn as many tokens as you need” policy on AI, the incentive is there for them to raise price and find an equilibrium point or at least reduce the bleed. | |
| ▲ | ethin 5 hours ago | parent | prev | next [-] | | I mean, the signs have been there that the costs to run and operate these models wasn't as simple as inference costs. And the signs were there (and, arguably, are still there) that it costs way, way more than many people like to claim on the part of Anthropic. So to me this price hike is not at all surprising. It was going to come eventually, and I suspect it's nowhere near over. It wouldn't surprise me if in 2-3 years the "max" plan is $800 or $2000 even. | | |
| ▲ | ezst 4 hours ago | parent [-] | | > It wouldn't surprise me if in 2-3 years the "max" plan is $800 or $2000 even. I'd rather be surprised if they are still doing business by then. |
| |
| ▲ | Lihh27 2 hours ago | parent | prev | next [-] | | heh adaptive thinking is letting the meter run itself. they make more when it runs longer. | |
| ▲ | paulddraper 6 hours ago | parent | prev [-] | | > The fact that Anthropic is rapidly trying to increase price may betray the fact that their recent lead is at the cost of dramatically higher operating costs. Or they are just not willing to burn obscene levels of capital like OpenAI. |
|
|
| ▲ | tabbott 2 hours ago | parent | prev | next [-] |
| I find it interesting that folks are so focused on cost for AI models. Human time spent redirecting AI coding agents towards better strategies and reviewing work, remains dramatically more expensive than the token cost for AI coding, for anything other than hobby work (where you're not paying for the human labor). $200/month is an expensive hobby, but it's negligible as a business expense; SalesForce licenses cost far more. The key question is how well it a given model does the work, which is a lot harder to measure. But I think token costs are still an order of magnitude below the point where a US-based developer using AI for coding should be asking questions about price; at current price points, the cost/benefit question is dominated by what makes the best use of your limited time as an engineer. |
| |
| ▲ | aenis 4 minutes ago | parent | next [-] | | That. We already shipped 3 things this year built using Claude. The biggest one was porting two native apps into one react native app - which was originally estimated to be a 6-7 month project for a 9 FTE team, and ended up being a 2 months project with 2 people. To me, the economic value of a claude subscription used right is in the range of 10-40k eur, depending on the type of work and the developer driving it. If Anthropic jacked the prices 100x today, I'd still buy the licenses for my guys. Edit: ok, if they charged 20k per month per seat I'd also start benchmarking the alternatives and local models, but for my business case, running a 700M a budget, Claude brings disproportionate benefis, not just in time saved in developer costs, but also faster shipping times, reduced friction between various product and business teams, and so on. For the first time we generally say 'yes' to whichever frivolities our product teams come up with, and thats a nice feeling. | |
| ▲ | hyraki an hour ago | parent | prev | next [-] | | Yes 200 as a business expense is really not that bad. But a hobby is hard to justify. | | |
| ▲ | scuff3d 4 minutes ago | parent [-] | | It's not gonna stay that way. Token cost is being massively subsidized right now. Prices will have to start increasing at some point. |
| |
| ▲ | vessenes 34 minutes ago | parent | prev [-] | | I mean, my openclaw instance was billing $200 a day for Opus after they banned using the max subscription. I think a fair amount of that was not useful use of Opus; so routing is the bigger problem. but, that sort of adds up, you know! At $1/hr, I loved Openclaw. At $15/hour, it's less competitive. |
|
|
| ▲ | _pdp_ 6 hours ago | parent | prev | next [-] |
| IMHO there is a point where incremental model quality will hit diminishing returns. It is like comparing an 8K display to a 16K display because at normal viewing distance, the difference is imperceptible, but 16K comes at significant premium. The same applies to intelligence. Sure, some users might register a meaningful bump, but if 99% can't tell the difference in their day-to-day work, does it matter? A 20-30% cost increase needs to deliver a proportional leap in perceivable value. |
| |
| ▲ | jasonjmcghee 3 minutes ago | parent | next [-] | | It's more like, if it gets it right 99% of the time, that sounds incredible. Until it's making 100k decisions a day and many are dependent on previous results. | |
| ▲ | highfrequency 3 hours ago | parent | prev | next [-] | | I believe that's why 90% of the focus in these firms is on coding. There is a natural difficulty ramp-up that doesn't end anytime soon: you could imagine LLMs creating a line of code, a function, a file, a library, a codebase. The problem gets harder and harder and is still economically relevant very high into the difficulty ladder. Unlike basic natural language queries which saturate difficulty early. This is also why I don't see the models getting commoditized anytime soon - the dimensionality of LLM output that is economically relevant keeps growing linearly for coding (therefore the possibility space of LLM outputs grows exponentially) which keeps the frontier nontrivial and thus not commoditized. In contrast, there is not much demand for 100 page articles written by LLMs in response to basic conversational questions, therefore the models are basically commoditized at answering conversational questions because they have already saturated the difficulty/usefulness curve. | | |
| ▲ | Aperocky an hour ago | parent [-] | | > the dimensionality of LLM output that is economically relevant keeps growing linearly for coding Doubt. Yes. there was at one point it suddenly became useful to write code in a general sense. I have seen almost no improvement in department of architecting, operations and gaslighting. In fact gaslighting has gotten worse. Entire output based on wrong assumption that it hid, almost intentionally. And I had to create very dedicated, non-agentic tools to combat this. And all of this with latest Opus line. |
| |
| ▲ | ZeroCool2u 5 hours ago | parent | prev | next [-] | | Whenever we get the locally runnable 4k models things are going to get really awkward for the big 3 labs. Well at least Google will still have their ad revenue I guess. | | |
| ▲ | UncleOxidant 5 hours ago | parent | next [-] | | Given how little claude usage they've been giving us on the "pro" plan lately, I've started doing more with the various open Qwen3.* models. Both Qwen3-coder-next and Qwen3.5-27b have been giving me good results and their 3.6 models are starting to be released. I think Anthropic may be shooting themselves in the foot here as more people start moving to local models due to costs and/or availability. Are the Qwen models as good as Claude right now? No. But they're getting close to as good as Claude sonnet was 9 months to a year ago (prior to 4.5, around 4.0). If I need some complex planning I save that for claude and have the Qwen models do the implementation. | |
| ▲ | robot_jesus 5 hours ago | parent | prev | next [-] | | They're not perfect but the local model game is progressing so quickly that they're impossible to ignore. I've only played around with the new qwen 3.6 models for a few minutes (it's damn impressive) but this weekend's project is to really put it through its paces. If I can get the performance I'm seeing out of free models on a 6-year-old Macbook Pro M1, it's a sign of things to come. Frontier models will have their place for 1) extensive integrations and tooling and 2) massive context windows. But I could see a very real local-first near future where a good portion of compute and inference is run locally and only goes to a frontier model as needed. | |
| ▲ | efficax 5 hours ago | parent | prev [-] | | If the apple silicon keeps making the gains it makes, a mac studio with 128gb of ram + local models will be a practical all-local workflow by say 2028 or 2030. OpenAI and Anthropic are going to have to offer something really incredible if they want to keep subscription revenue from software developers in the near future, imo |
| |
| ▲ | levocardia 4 hours ago | parent | prev | next [-] | | Depends a lot on the task demands. "Got 95% of the way to designing a successful drug" and "Got 100% of the way" is a huge difference in terms of value, and that small bump in intelligence would justify a few orders of magnitude more in cost. | | |
| ▲ | 9dev 4 hours ago | parent [-] | | But that objective measure is exactly what we’re lacking in programming: There is often many ways to skin a cat, but the model only takes one. Without knowing about those it didn’t take, how do you judge the quality of a new model? |
| |
| ▲ | Rapzid 35 minutes ago | parent | prev | next [-] | | At normal viewing distance(let's say cinema FOV) most people won't see a difference between 4k and 8k never mind 16k. And it's not that they "don't notice" it's that they physically can't distinguish finer angular separation. | |
| ▲ | snek_case 6 hours ago | parent | prev | next [-] | | It probably depends what you're using the models for. If you use them for web search, summarizing web pages, I can imagine there's a plateau and we're probably already hitting it. For coding though, there is kind of no limit to the complexity of software. The more invariants and potential interactions the model can be aware of, the better presumably. It can handle larger codebases. Probably past the point where humans could work on said codebases unassisted (which brings other potential problems). | | |
| ▲ | Bolwin an hour ago | parent [-] | | > summarizing web pages For summarizing creative writing, I've found Opus and Gemini 3 pro are still only okay and actively bad once it gets over 15K tokens or so. A lot of long context and attention improvements have been focused on Needle in a Haystack type scenarios, which is the opposite of what summarization needs. |
| |
| ▲ | simplyluke 5 hours ago | parent | prev | next [-] | | I'm seeing a lot of sentiment, and agree with a lot of it, that opus 4.6 un-nerfed is there already and for many if not most software use cases there's more value to be had in tooling, speed, and cost than raw model intelligence. | |
| ▲ | aray07 6 hours ago | parent | prev | next [-] | | yeah thats is my biggest issue - im okay with paying 20-30% more but what is the ROI? i dont see an equivalent improvement in performance. Anthropic hasnt published any data around what these improvements are - just some vague “better instruction following" | | |
| ▲ | Bridged7756 4 hours ago | parent | next [-] | | Its enshittificating real fast. They'll just keep releasing model after model, more expensive than the last, marginal gains, but touted as "the next thing". Evangelists will say that they're afraid, it's the future, in 6 months it's all over. Anthropic will keep astroturfing on Reddit. CEOs will make even more outlandish claims. You raised a good point, what's a good metric for LLM performance? There's surely all the benchmarks out there, but aren't they one and done? Usually at release? What keeps checking the performance of those models. At this point it's just by feel. People say models have been dumbed down, and that's it. I think the actual future is open source models. Problem is, they don't have the huge marketing budget Anthropic or OpenAI does. | |
| ▲ | margorczynski 4 hours ago | parent | prev [-] | | The other thing is most people don't really care about price per token or whatever but how much it will cost to execute (successfully) a task they want. It doesn't matter if a model is e.g. 30% cheaper to use than another (token-wise) but I need to burn 2x more tokens to get the same acceptable result. |
| |
| ▲ | mlinsey 5 hours ago | parent | prev | next [-] | | I agree, but also the model intelligence is quite spikey. There are areas of intelligence that I don't care at all about, except as proxies for general improvement (this includes knowledge based benchmarks like Humanity's Last Exam, as well as proving math theorems etc). There are other areas of intelligence where I would gladly pay more, even 10X more, if it meant meaningful improvements: tool use, instruction following, judgement/"common sense", learning from experience, taste, etc. Some of these are seeing some progress, others seem inherent to the current LLM+chain of thought reasoning paradigm. | | |
| ▲ | manmal 3 hours ago | parent [-] | | Common sense isn’t a language pattern. I doubt this will ever work w/ LLMs. |
| |
| ▲ | mgraczyk 4 hours ago | parent | prev | next [-] | | This will probably happen but I wouldn't plan on it happening soon | |
| ▲ | _pdp_ 5 hours ago | parent | prev | next [-] | | Longer version of the comment https://www.linkedin.com/pulse/imperceptible-upgrade-petko-d... | |
| ▲ | zadkey 2 hours ago | parent | prev | next [-] | | yeah there needs to be a corresponding increment improvement in model archetecture. | |
| ▲ | nisegami 5 hours ago | parent | prev | next [-] | | >IMHO there is a point where incremental model quality will hit diminishing returns. It's not necessary a single discrete point I think. In my experience, it's tied to the quality/power of your harness and tooling. More powerful tooling has made revealed differences between models that were previously not easy to notice. This matches your display analogy, because I'm essentially saying that the point at which display resolution improvements are imperceptible matters on how far you sit. | |
| ▲ | wellthisisgreat 4 hours ago | parent | prev | next [-] | | Does anyone here use 8k display for work? Does it make sense over 4k? I was always wondering where that breaking point for cost/peformance is for displays. I use 4K 27” and it’s noticeably much better for text than 1440p@27 but no idea if the next/ and final stop is 6k or 8k? | | |
| ▲ | zozbot234 3 hours ago | parent [-] | | Even 4k turns out to be overkill if you're looking at the whole screen and a pixel-perfect display. By human visual acuity, 1440p ought to be enough, and even that's taking a safety margin over 1080p to account for the crispness of typical text. |
| |
| ▲ | iLoveOncall 4 hours ago | parent | prev [-] | | > IMHO there is a point where incremental model quality will hit diminishing returns. You mean a couple of years ago? |
|
|
| ▲ | speedgoose 5 hours ago | parent | prev | next [-] |
| The "multiplier" on Github Copilot went from 3 to 7.5. Nice to see that it is actually only 20-30% and Microsoft wanting to lose money slightly slower. https://docs.github.com/fr/copilot/reference/ai-models/suppo... |
| |
| ▲ | Someone1234 5 hours ago | parent | next [-] | | Yep, and I just made a recommendation that was essentially "never enable Opus 4.7" to my org as a direct result. We have Opus 4.6 (3x) and Opus 4.5 (3x) enabled currently. They are worth it for planning. At 7.5x for 4.7, heck no. It isn't even clear it is an upgrade over Opus 4.6. | | |
| ▲ | chewz 2 hours ago | parent | next [-] | | 7.5 is promotional rate, it will go up to 25. And in May you will be switched to per token billing. Opus 4.5 and 4.6 will be removed very soon. So what is your contingency plan? | |
| ▲ | GaryBluto 4 hours ago | parent | prev | next [-] | | Microsoft are going to be removing Opus 4.5 and 4.6 from Copilot soon so I'd enjoy the lower cost while it lasts. | |
| ▲ | bwat49 4 hours ago | parent | prev | next [-] | | in copilot I find it hard to justify using opus at even 3x vs just using GPT 5.4 high at 1x | |
| ▲ | solenoid0937 2 hours ago | parent | prev [-] | | I don't know how you guys are not seeing 4.7 as an upgrade, it just does so much more, so much better. I guess lower complexity tasks are saturated though. |
| |
| ▲ | aulin an hour ago | parent | prev [-] | | Opus 4.6 also just got dumber. It's dismissive, hand-wavy, jumps to conclusions way too quickly, skips reasoning... Bubble is going to burst, either some big breakthrough comes up or we are going to see a very fast enshittificafion. |
|
|
| ▲ | namnnumbr 5 hours ago | parent | prev | next [-] |
| The title is a misdirection. The token counts may be higher, but the cost-per-task may not be for a given intelligence level. Need to wait to see Artificial Analysis' Intelligence Index run for this, or some other independent per-task cost analysis. The final calculation assumes that Opus 4.7 uses the exact same trajectory + reasoning output as Opus 4.6.
I have not verified, but I assume it not to be the case, given that Opus 4.7 on Low thinking is strictly better than Opus 4.6 on Medium, etc., etc. |
| |
| ▲ | alach11 an hour ago | parent | next [-] | | I ran an internal (oil and gas focused) benchmark yesterday and found Opus 4.7 was 50% cheaper than Opus 4.6, driven by significantly fewer output tokens for reasoning. It also scored 80% (vs. 60%). | |
| ▲ | dang 41 minutes ago | parent | prev | next [-] | | (Submitted title was "Claude Opus 4.7 costs 20–30% more per session". We've since changed it to a (more neutral) version of what the article's title says.) | |
| ▲ | bisonbear 4 hours ago | parent | prev | next [-] | | yep, ran a controlled experiment on 28 tasks comparing old opus 4.6 vs new opus 4.6 vs 4.7, and found that 4.7 is comparable in cost to old 4.6, and ~20% more expensive then new 4.6 (because new 4.6 is thinking less) https://www.stet.sh/blog/opus-4-7-zod | | |
| ▲ | cced 4 hours ago | parent [-] | | So they nerfed 4.6 to make way for 4.7? Progress. /s |
| |
| ▲ | aray07 5 hours ago | parent | prev | next [-] | | im running some experiments on this but based on what i have seen on my own personal data - I dont think this is true "given that Opus 4.7 on Low thinking is strictly better than Opus 4.6 on Medium, etc., etc.” Opus 4.7 in general is more expensive for similar usage. Now we can argue that is provides better performance all else being equal but I haven’t been able to see that | |
| ▲ | namnnumbr 3 hours ago | parent | prev | next [-] | | Following up on "strictly better" via plot in release announcement: https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-... | |
| ▲ | unpwn 5 hours ago | parent | prev [-] | | Very unlikely that the article is wrong. the 4.7 intelligence bump is not that big, plus most of the token spend is in inputs/tool calls etc, much of which won't change even with this bump. | | |
| ▲ | namnnumbr 3 hours ago | parent [-] | | IMO, you're incorrect: 1. In my own use, since 1 Apr this month, very heavy coding: > 472.8K Input Tokens +299.3M cached
> 2.2M Output Tokens My workloads generate ~5x more output than input, and output tokens cost 5x more per token... output dominates my bill at roughly 25x the cost of input. (Even more so when you consider cache hits!)
If Opus 4.7 was more efficient with reasoning (and thus output), I'd likely save considerable money (were I paying per-token). 2. Anthropic's benchmarks DO show strictly-better (granted they are Anthropic's benchmarks, so salt may be needed)
https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-... |
|
|
|
| ▲ | ericol 2 hours ago | parent | prev | next [-] |
| I did some work yesterday with Opus and found it amazing. Today we are almost on non-speaking terms.
I'm asking it to do some simple stuff and he's making incredible stupid mistakes: This is the third time that I have to ask you to remove the issue that was there for more than 20 hours. What is going on here?
and at the same time the compacting is firing like crazy. (What adds ~4 minute delays every 1 - 15 minutes) | # | Time | Gap before | Session span | API calls |
|---|----------|-----------|--------------|-----------|
| 1 | 15:51:13 | 8s | <1m | 1 |
| 2 | 15:54:35 | 48s | 37m | 51 |
| 3 | 16:33:33 | 2s | 19m | 42 |
| 4 | 16:53:44 | 1s | 9m | 30 |
| 5 | 17:04:37 | 1s | 17m | 30 |
# — sequential compaction event number, ordered by time.
Time — timestamp of the first API call in the resumed session, i.e. when the new context (carrying the compaction summary) was first sent to the
model.
Gap before — time between the last API call of the prior session and the first call of this one. Includes any compaction processing time plus user
think time between the two sessions.
Session span — how long this compaction-resumed session ran, from its first API call to its last before the next compaction (or end of session).
API calls — total number of API requests made during this resumed session. Each tool use, each reply, each intermediate step = one request.
Bottomline, I will probably stay on Sonnet until they fix all these issues. |
| |
| ▲ | aulin an hour ago | parent | next [-] | | They won't. These are not "issues", it's them trying to push the models to burn less compute. It will only get worse. | | | |
| ▲ | cadamsdotcom 43 minutes ago | parent | prev | next [-] | | > he’s making .. mistakes Claude and other LLMs do not have a gender; they are not a “he”. Your LLM is a pile of weights, prompts, and a harness; anthropomorphising like this is getting in the way. You’re experiencing what happens when you sample repeatedly from a distribution. Given enough samples the probability of an eventual bad session is 100%. Just clear the context, roll back, and go again. This is part of the job. | | | |
| ▲ | whalesalad 2 hours ago | parent | prev [-] | | I am having a shit experience lately. Opus 4.7, max effort. > You're right, that was a shit explanation. Let me go look at what V1 MTBL actually is before I try again. > Got it — I read the V1 code this time instead of guessing. Turns out my first take was wrong in an important way. Let me redo this in English. :facepalm: | | |
| ▲ | tremon 2 hours ago | parent | next [-] | | > I read the V1 code this time instead of guessing Does the LLM even keep a (self-accessible) record of previous internal actions to make this assertion believable, or is this yet another confabulation? | |
| ▲ | al_borland 2 hours ago | parent | prev | next [-] | | This seems like the experience I've had with every model I've tried over the last several years. It seems like an inherent limitation of the technology, despite the hyperbolic claims of those financially invested in all of this paying off. | |
| ▲ | ericol 2 hours ago | parent | prev | next [-] | | Matches what I am experiencing. Makes incredible stupid mistakes. The weird stuff is yesterday I asked it to test and report back on a 30+ commit branch for a PR and it did that flawlessly. | |
| ▲ | ed_elliott_asc an hour ago | parent | prev | next [-] | | If it isn’t working for you why don’t you choose an older model? 4.6 | |
| ▲ | alphabettsy an hour ago | parent | prev [-] | | The docs suggest not using max effort in most cases to avoid overthinking :shrug: |
|
|
|
| ▲ | _fat_santa 5 hours ago | parent | prev | next [-] |
| A question I've been asking alot lately (really since the release of GPT-5.3) is "do I really need the more powerful model"? I think a big issue with the industry right now is it's constantly chasing higher performing models and that comes at the cost of everything else. What I would love to see in the next few years is all these frontier AI labs go from just trying to create the most powerful model at any cost to actually making the whole thing sustainable and focusing on efficiency. The GPT-3 era was a taste of what the future could hold but those models were toys compare to what we have today. We saw real gains during the GPT-4 / Claude 3 era where they could start being used as tools but required quite a bit of oversight. Now in the GPT-5 / Claude 4 era I don't really think we need to go much further and start focusing on efficiency and sustainability. What I would love the industry to start focusing on in the next few years is not on the high end but the low end. Focus on making the 0.5B - 1B parameter models better for specific tasks. I'm currently experimenting with fine-tuning 0.5B models for very specific tasks and long term I think that's the future of AI. |
| |
| ▲ | namnnumbr 3 hours ago | parent | next [-] | | Yes! I'd be totally happy with today's sonnet 4.6 if I could run it locally. If you can forgive the obviously-AI-generated writing, [CPUs Aren't Dead](https://seqpu.com/CPUsArentDead) makes an interesting point on AI progress: Google's latest, smallest Gemma model (Gemma 4 E2B), which can run on a cell phone, outperforms GPT-3.5-turbo.
Granted, this factoid is based on `MT-Bench` performance, a benchmark from 2023 which I assume to be both fully saturated and leaked into the training data for modern LLMs.
However, cross-referencing [Artificial Analysis' Intelligence Index](https://artificialanalysis.ai/models?models=gemma-4-e2b-non-...) suggests that indeed the latest 2B open-weights models are capable of matching or beating 175B models from 3-4 years ago.
Perhaps more impressive, [Gemma 4 E4B matches or beats GPT-4o](https://artificialanalysis.ai/models?models=gemma-4-e4b%2Cge...) on many benchmarks. If this trend continues, perhaps we'll have the capabilities of today's best models available to reasonably run on our laptops! | |
| ▲ | minimaxir 4 hours ago | parent | prev | next [-] | | Many people were hoping that Sonnet 4.6 was "Opus 4.5 quality but with Sonnet speed/cost" but unfortunately that didn't pan out. | | |
| ▲ | malfist 2 hours ago | parent [-] | | You can already see people here saying the same stuff about opus 4.7, saw a comment claiming that Opus 4.7 on low thinking was better than 4.6 on high. I'm not seeing that in my testing, but these opinions are all vibe based anyway. |
| |
| ▲ | Bridged7756 4 hours ago | parent | prev | next [-] | | Efficiency doesn't make as much money. It's in big LLM's best interest to keep inference computationally expensive. I personally think the whole "the newest model is crazy! You've gotta use X (insert most expensive model)" Is just FOMO and marketing-prone people just parroting whatever they've seen in the news or online. | |
| ▲ | renticulous 3 hours ago | parent | prev | next [-] | | Does everyone need a graphing calculator? Does everyone need a scientific calculator? Does everyone need a normal calculator? Does everyone need GeoGebra or Desmos ? | |
| ▲ | nprateem 33 minutes ago | parent | prev | next [-] | | So you're happy with an untrustworthy lazy moron prone to stupid mistakes and guesswork? Surely you can see the first lab that solves this gains a massive advantage? | |
| ▲ | fkealy 5 hours ago | parent | prev [-] | | I agree, and yet here i am using it... However, I think the industry IS going multiple directions all at once with smaller models, bigger models etc. I need to try out Google's latest models but alas what can one person do in the face of so many new models... |
|
|
| ▲ | admiralrohan 2 hours ago | parent | prev | next [-] |
| In Kolkata, sweet sellers was struggling with cost management after covid due to increased prices of raw materials. But they couldn't increase the price any further without losing customers. So they reduced the size of sweets instead, and market slowly reduced expectations. And this is the new normal now. Human psychology is surprisingly similar, and same pattern comes across domains. |
| |
|
| ▲ | montjoy 5 hours ago | parent | prev | next [-] |
| It appears that they are testing using Max. For 4.7 Anthropic recognizes the high token usage of max and recommends the new xhigh mode for most cases. So I think the real question is whether 4.7 xhigh is “better” than 4.6 max. > max: Max effort can deliver performance gains in some use cases, but may show diminishing returns from increased token usage. This setting can also sometimes be prone to overthinking. We recommend testing max effort for intelligence-demanding tasks. > xhigh (new): Extra high effort is the best setting for most coding and agentic use cases Ref: https://platform.claude.com/docs/en/build-with-claude/prompt... |
| |
| ▲ | dcrazy 5 hours ago | parent [-] | | Inserting an xhigh tier and pushing max way out has very “these go to 11” vibes. |
|
|
| ▲ | uberman 7 hours ago | parent | prev | next [-] |
| On actual code, I see what you see a 30% increase in tokens which is in-line with what they claim as well. I personally don't tend to feed technical documentation or random pros into llms. Given that Opus 4.6 and even Sonnet 4.6 are still valid options, for me the question is not "Does 4.7 cost more than claimed?" but "What capabilities does 4.7 give me that 4.6 did not?" Yesterday 4.6 was a great option and it is too soon for me to tell if 4.7 is a meaningful lift. If it is, then I can evaluate if the increased cost is justified. |
| |
| ▲ | tetha 4 hours ago | parent | next [-] | | Yeah that was an interesting discovery in a development meeting. Many people were chasing after the next best model and everything, though for me, Sonnet 4.6 solves many topics in 1-2 rounds. I mainly need some focus on context, instructions and keeping tasks well-bounded. Keeping the task narrow also simplifies review and staying in control, since I usually get smaller diffs back I can understand quickly and manage or modify later. I'll look at the new models, but increasing the token consumptions by a factor of 7 on copilot, and then running into all of these budget management topics people talk about? That seems to introduce even more flow-breakers into my workflow, and I don't think it'll be 7 times better. Maybe in some planning and architectural topics where I used Opus 4.6 before. | |
| ▲ | pier25 6 hours ago | parent | prev | next [-] | | haven't people been complaining lately about 4.6 getting worse? | | | |
| ▲ | grim_io 6 hours ago | parent | prev [-] | | How long will they host 4.6? Maybe longer for enterprise, but if you have a consumer subscription, you won't have a choice for long, if at all anymore. | | |
| ▲ | Jeremy1026 6 hours ago | parent | next [-] | | I was trying to figure out earlier today how to get 4.6 to run in Claude Code, as part of the output it included "- Still fully supported — not scheduled for retirement until Feb 2027." Full caveat of, I don't know where it came up with this information, but as others have said, 4.5 is still available today and it is now 5, almost 6 months old. | |
| ▲ | hypercube33 5 hours ago | parent | prev | next [-] | | I'm still using 4.5 because it gets the niche work I'm using it for where 4.6 would just fight me. | |
| ▲ | nfredericks 6 hours ago | parent | prev [-] | | Opus 4.5 is still available |
|
|
|
| ▲ | atonse 6 hours ago | parent | prev | next [-] |
| Just yesterday I was happy to have gotten my weekly limit reset [1]. And although I've been doing a lot of mockup work (so a lot of HTML getting written), I think the 1M token stuff is absolutely eating up tokens like CRAZY. I'm already at 27% of my weekly limit in ONE DAY. https://news.ycombinator.com/item?id=47799256 |
| |
| ▲ | jabart 6 hours ago | parent | next [-] | | I'm seeing the opposite. With Opus 4.7 and xhigh, I'm seeing less session usage , it's moving faster, and my weekly usage is not moving that much on a Team Pro account. | |
| ▲ | richstokes an hour ago | parent | prev | next [-] | | My personal Claude sub (Pro), I can burn through my limit in a couple of hours when using Opus. It's borderline unusable unless you're willing to pay for extended usage or artificially slow yourself down. | | |
| ▲ | tabbott 36 minutes ago | parent [-] | | To me, it seems like the Pro tier is priced for using Sonnet a lot or Opus a little, and Max for using Opus a lot. So that seems about what you should expect. |
| |
| ▲ | cbm-vic-20 5 hours ago | parent | prev | next [-] | | Four day workweek! | |
| ▲ | aray07 6 hours ago | parent | prev | next [-] | | yeah similar for me - it uses a bunch more tokens and I haven’t been able to tell the ROI in terms of better instruction following it seems to hallucinate a bit more (anecdotal) | | | |
| ▲ | CharlesW 5 hours ago | parent | prev | next [-] | | > I'm already at 27% of my weekly limit in ONE DAY. Ouch, that's very different than experience. What effort level? Are you careful to avoid pushing session context use beyond 350k or so (assuming 1m context)? | | |
| ▲ | atonse 3 hours ago | parent | next [-] | | Yeah fair point. I have had a couple of conversations (ingesting a pretty complex domain and creating about 42 high fidelity tailwind mockups with ui.sh). And this particular set of things has context routinely hit 350-450k before I compact. That's likely what it is? I think this particular work stream is eating a lot of tokens. Earlier this week (before Open 4.7 hit), I just turned off 1m context and had it grow a lot slower. I also have it on high all the time. Medium was starting to feel like it was making the occasional bad decisions and also forgetting things more. | |
| ▲ | JimmaDaRustla 4 hours ago | parent | prev [-] | | I'm mind blown people are complaining about token consumption and not communicating what thinking level they're using - if cost is a concern and you're paying any attention, you'd be starting with medium and seeing if you can get better results with less tokens. Every person complaining about token usage seem to have no methodology - probably using max and completely oblivious. |
| |
| ▲ | sreekanth850 5 hours ago | parent | prev | next [-] | | Iam at 22%, just two task. A bug fixing and a Scalar integration. | |
| ▲ | AndyNemmity 4 hours ago | parent | prev [-] | | I'm at 35% :( |
|
|
| ▲ | sipsi 6 hours ago | parent | prev | next [-] |
| I tried to do my usual test (similar to pelican but a bit more complex) but it ran out of 5 hour limit in 5 minutes. Then after 5 hours I said "go on" and the results were the worst I've ever seen. |
|
| ▲ | jmward01 5 hours ago | parent | prev | next [-] |
| Claude code seems to be getting worse on several fronts and better on others. I suspect product is shifting from 'make it great' to 'make it make as much money for us as possible and that includes gathering data'. Recently it started promoting me for feedback even though I am on API access and have disabled this. When I did a deep dive of their feedback mechanism in the past (months ago so probably changed a lot since then) the feedback prompt was pushing message ids even if you didn't respond. If you are on API usage and have told them no to training on your data then anything pushing a message id implies that it is leaking information about your session. It is hard to keep auditing them when they push so many changes so I am now 'default they are stealing my info' instead of believing their privacy/data use policy claims. Basically, my level of trust is eroding fast in their commitment to not training on me and I am paying a premium to not have that happen. |
|
| ▲ | yuanzhi1203 5 hours ago | parent | prev | next [-] |
| We noticed this two weeks ago where we found some of our requests are unexpected took more tokens than measured by count_tokens call. At the end they were Anthropic's A/B testing routing some Opus 4.6 calls to Opus 4.7. https://matrix.dev/blog-2026-04-16.html (We were talking to Opus 4.7 twelve days ago) |
|
| ▲ | qq66 6 hours ago | parent | prev | next [-] |
| This is the backdoor way of raising prices... just inflate the token pricing. It's like ice cream companies shrinking the box instead of raising the price |
| |
| ▲ | Bridged7756 4 hours ago | parent [-] | | No, you're forgetting the never ending world shattering models being released every couple of months. Each one with 2X token costs of course, for a vague performance gain and that will deprecate the previous ones. | | |
|
|
| ▲ | margorczynski 4 hours ago | parent | prev | next [-] |
| It doesn't look good for Anthropic, especially considering they are burning billions in investor money. Looks like they lost the mandate of heaven, if Open AI plays it right it might be their end. Add to that the open source models from China. |
| |
| ▲ | throwaway041207 4 hours ago | parent | next [-] | | I work at a company that has gone all in on Anthropic, and we're just shoveling money at them. I suspect there are a more enterprises than we realize that are doing this. When I read these comments on Hacker News, I see a lot of people miffed about their personal subscription limits. I think this is a viewpoint that is very consumer focused, and probably within Anthropic they're seeing buckets of money being dumped on them from enterprises. They probably don't really care as much about the individual subscription user, especially power users. | |
| ▲ | solenoid0937 2 hours ago | parent | prev | next [-] | | 1. HN is so unrepresentative of real life. You have people on their $20/$200 subscriptions complaining about usage limits. They are a tiny fraction of Anthropic's revenue. API billing and enterprise is where the money is. 2. Anthropic and OpenAI's financials are totally different. The former has nearly the same RRR and a fraction of the cash burn. There is a reason Anthropic is hot on secondary and OAI isn't | |
| ▲ | therobots927 4 hours ago | parent | prev [-] | | OpenAI is dealing with exactly the same energetic and financial constraints as Anthropic. That will become apparent soon. |
|
|
| ▲ | 2001zhaozhao an hour ago | parent | prev | next [-] |
| To me, all of this seems to be pointing to the future solution being some sort of diffusion-based LLM that can process multiple tokens per pass, while keeping the benefits of more "verbose" token encoding. |
|
| ▲ | jmward01 6 hours ago | parent | prev | next [-] |
| Yeah. I just did a day with 4.7 and I won't be going back for a while. It is just too expensive. On top of the tokenization the thinking seems like it is eating a lot more too. |
| |
| ▲ | aray07 6 hours ago | parent | next [-] | | yeah i am still not clear why there are 5 effort modes now on top of more expensive tokenization | | |
| ▲ | jmward01 3 hours ago | parent | next [-] | | choice is often a great dark-pattern (lack of choice is too but...). Choices generally grow cost to discover optimality in an np way. This means if the entity giving choice has more ability to compute the value prop than the entity deciding the choice you can easily create an exploitive system. Just create a bunch of choices, some actually do save money with enough thought but most don't, and you will gain: People that think they got what they wanted, the feature is there!, so they can't complain but... People that end up essentially randomly picking so the average value of the choices made by customers is suboptimal. | |
| ▲ | jddj 6 hours ago | parent | prev [-] | | Once you've seen a few results of an LLM given too much sway over product decisions, 5 effort modes expressed as various english adjectives is pretty much par for the course |
| |
| ▲ | JimmaDaRustla 4 hours ago | parent | prev [-] | | What was your level methodology and results? Can't just post "too expensive" and not explain how you went about it. |
|
|
| ▲ | TomGarden an hour ago | parent | prev | next [-] |
| Asked Opus 4.7 to extend an existing system today. After thorough exploration and a long back and forth on details it came up with a plan. Then proceeded to build a fully parallel, incompatible system from scratch with the changes I wanted but everything else incompatible and full of placeholders |
|
| ▲ | jstummbillig 3 hours ago | parent | prev | next [-] |
| "One session" is not a very interesting unit of work. What I am interested in is how much less work I am required to do, to get the results I want. This is not so much about my instructions being followed more closely. It's the LLM being smarter about what's going on and for example saving me time on unnecessary expeditions. This is where models have been most notably been getting better to my experience. Understanding the bigger picture. Applying taste. It's harder to measure, of course, but, at least for my coding needs, there is still a lot of room here. If one session costs an additional 20% that's completely fine, if that session gets me 20% closer to a finished product (or: not 20% further away). Even 10% closer would probably still be entirely fine, given how cheap it is. |
|
| ▲ | technotony 5 hours ago | parent | prev | next [-] |
| Not only that but they seem to have cut my plan ability to use Sonnet too. I have a routine that used to use about 40% of my 5 hour max plan tokens, then since yesterday it gets stopped because it uses the whole 100%. Anyone else experience this? |
| |
| ▲ | mfro 5 hours ago | parent [-] | | yeah it seems like sonnet 4.6 burns thru tokens crazy fast. I did one prompt, sonnet misunderstood it as 'generate an image of this' and used all of my free tokens. |
|
|
| ▲ | taosx 5 hours ago | parent | prev | next [-] |
| Claude seems so frustrating lately to the point where I avoid and completely ignore it. I can't identify a single cause but I believe it's mostly the self-righteousness and leadership that drive all the decisions that make me distrust and disengage with it. |
| |
| ▲ | QuercusMax 4 hours ago | parent | next [-] | | What do you mean by this? What are you frustrated by? You're offended by their political beliefs, so you don't like the way the model works? | |
| ▲ | estearum 5 hours ago | parent | prev [-] | | using dumber models to own the libs | | |
| ▲ | testbjjl 5 hours ago | parent [-] | | Definitely experimenting with less expensive ones. I have a few versions of my settings.json I also wonder if token utilization has or will ever find its way to employee performance reviews as these models go up in price. |
|
|
|
| ▲ | Yukonv 6 hours ago | parent | prev | next [-] |
| Some broad assumptions are being made that plans give you a precise equivalent to API cost. This is not the case with reverse engineering plan usage showing cached input is free [0]. If you re-run the math removing cached input the usage cost is ~5-34% more. Was the token plan budget increase [1] proportional to account for this? Can’t say with certainty. Those paying API costs though the price hike is real. [0] https://she-llac.com/claude-limits [1] https://xcancel.com/bcherny/status/2044839936235553167 |
|
| ▲ | iknowstuff 6 hours ago | parent | prev | next [-] |
| Interesting because I already felt like current models spit out too much garbage verbose code that a human would write in a far more terse, beautiful and grokable way |
| |
| ▲ | aray07 6 hours ago | parent | next [-] | | yeah opus 4.7 feels a lot more verbose - i think they changed the system prompt and removed instructions to be terse in its responses | |
| ▲ | QuercusMax 4 hours ago | parent | prev [-] | | I had a case yesterday where Claude wrote me a series of if/elses in python. I asked it if it could use some newer constructs instead, and it told me that I was on a new enough python version that I could use match/case. Great! And then it proceeded to rewrite the block with a dict lookup plus if-elses, instead of using match/case. I had to nag it to actually rewrite the code the way it said it would! |
|
|
| ▲ | adaptive_loop 5 hours ago | parent | prev | next [-] |
| Every time a new model comes out, I'm left guessing what it means for my token budget in order to sustain the quality of output I'm getting. And it varies unpredictably each time. Beyond token efficiency, we need benchmarks to measure model output quality per token consumed for a diverse set of multi-turn conversation scenarios. Measuring single exchanges is not just synthetic, it's unrealistic. Without good cost/quality trade-off measures, every model upgrade feels like a gamble. |
| |
| ▲ | bityard 4 hours ago | parent | next [-] | | The company I work for provides all engineering employees with a Claude subscription. My job isn't writing (much) code, and we have Copilot with MS Office, plus multiple internal AI tools on top of that. So I'm free to do low-stakes experiments on Claude without having to worry about hitting my monthly usage limit. I am finding that for complex tasks, Claude's quality of output varies _tremendously_ with repeated runs of the same model and prompt. For example, last week I wrote up (with my own brain and keyboard) a somewhat detailed plain english spec of a work-related productivity app that I've always wanted but never had the time to write. It was roughly the length of an average college essay. The first thing I asked Claude to do was not write any code, but come up with a more formal design and implementation plan based on the requirements that I gave. The idea was to then hand _that_ to Claude and say, okay, now build it. I used Opus 4.6 with High reasoning for all of this and did not change any model settings between runs. The first run was overall _amazing_. It was detailed, well-written, contained everything that I asked for. The only drawback was that I was ambiguous on a couple of points which meant that the model went off and designed something in a way that I wasn't expecting and didn't intend. So I cleared that up in my prompt, and instead of keeping the context and building on what was already there, I started a new chat and had it start again from scratch. What it wrote the second time was _far_ less impressive. The writing was terse, there was a lot less detail, the pretty dependency charts and various tables it made the first time were all gone. Lots of stuff was underspecified or outright missing. New chat, start again. Similar results as the second run, maybe a bit worse. It also started _writing code_ which was something I told it NOT to do. At this point I'm starting to panic a little because I'm sure I didn't add, "oh, and make it crappy" to the prompt and I was a little angry about not saving the first iteration since it was fairly close to what I had wanted anyway. I decided to try one last time and it finally gave me back something within about 95% of the first run in terms of quality, but with all the problems fixed. So, I was (finally) happy with that, and it used that to generate the application surprisingly well, with only a few issues that should not be too hard to fix after the fact. So I guess 4th time was a charm, and the fare was about $7 in tokens to get there. | |
| ▲ | therobots927 5 hours ago | parent | prev [-] | | That’s the joy of purchasing an intangible and non-deterministic product. The profit margin is completely within the vendor’s control and quality is hard for users to measure. |
|
|
| ▲ | sysmax 5 hours ago | parent | prev | next [-] |
| Well, LLMs are priced per token, and most of the tokens are just echoing back the old code with minimal changes. So, a lot of the cost is actually paying for the LLM to echo back the same code. Except, it's not that trivial to solve. I tried experimenting with asking the model to first give a list of symbols it will modify, and then just write the modified symbols. The results were OK, but less refined than when it echoes back the entire file. The way I see it is that when you echo back the entire file, the process of thinking "should I do an edit here" is distributed over a longer span, so it has more room to make a good decision. Like instead of asking "which 2 of the 10 functions should you change" you're asking it "should you change method1? what about method2? what about method3?", etc., and that puts less pressure on the LLM. Except, currently we are effectively paying for the LLM to make that decision for *every token*, which is terribly inefficient. So, there has to be some middle ground between expensively echoing back thousands of unchanged tokens and giving an error-ridden high-level summary. We just haven't found that middle ground yet. |
| |
| ▲ | mmastrac 5 hours ago | parent | next [-] | | I think the ideal way for these LLMs to work will be using AST-level changes instead of "let me edit this file". grit.io was working on this years ago, not sure if they are still alive/around, but I liked their approach (just had a very buggy transformer/language). | |
| ▲ | gruez 5 hours ago | parent | prev [-] | | >and most of the tokens are just echoing back the old code with minimal changes I thought coding harnesses provided tools to apply diffs so the LLM didn't have to echo back the entire file? | | |
| ▲ | sysmax 5 hours ago | parent [-] | | They can, but this reduces the quality. The LLM has a harder time picking the first edit, and then all subsequent work is influenced by that one edit. Like first creating an unnecessary auxiliary type, and then being stuck modifying the rest of the code to work with it. So, in practice, many tools still work on the file level. |
|
|
|
| ▲ | beej71 5 hours ago | parent | prev | next [-] |
| News like this always makes me wonder about running my own model, something I've never done. A couple thousand bucks can get you some decent hardware, it looks like, but is it good for coding? What is your all's experience? And if it's not good enough for coding, what kind of money, if any, would make it good enough? |
| |
| ▲ | arcanemachiner 5 hours ago | parent | next [-] | | I want to give give you realistic expectations: Unless you spend well over $10K on hardware, you will be disappointed, and will spend a lot of time getting there. For sophisticated coding tasks, at least. (For simple agentic work, you can get workable results with a 3090 or two, or even a couple 3060 12GBs for half the price. But they're pretty dumb, and it's a tease. Hobby territory, lots of dicking around.) Do yourself a favor: Set up OpenCode and OpenRouter, and try all the models you want to try there. Other than the top performers (e.g. GLM 5.1, Kimi K2.5, where required hardware is basically unaffordable for a single person), the open models are more trouble than they're worth IMO, at least for now (in terms of actually Getting Shit Done). | | |
| ▲ | _345 4 hours ago | parent [-] | | We need more voices like this to cut through the bullshit. It's fine that people want to tinker with local models, but there has been this narrative for too long that you can just buy more ram and run some small to medium sized model and be productive that way. You just can't, a 35b will never perform at the level of the same gen 500b+ model. It just won't and you are basically working with GPT-4 (the very first one to launch) tier performance while everyone else is on GPT-5.4. If that's fine for you because you can stay local, cool, but that's the part that no one ever wants to say out loud and it made me think I was just "doing it wrong" for so long on lm studio and ollama. |
| |
| ▲ | efficax 41 minutes ago | parent | prev | next [-] | | gemma4 and qwen3.6 are pretty capable but will be slower and wrong more often than the larger models. But you can connect gemma4 to opencode via ollama and it.. works! it really can write and analyze code. It's just slow. You need serious hardware to run these fast, and even then, they're too small to beat the "frontier" models right now. But it's early days | |
| ▲ | __mharrison__ 4 hours ago | parent | prev | next [-] | | My anecdotal experience with a recent project (Python library implemented and released to pypi). I took the plan that I used from Codex and handed it to opencode with Qwen 3.5 running locally. It created a library very similar to Codex but took 2x longer. I haven't tried Qwen 3.6 but I hear it's another improvement. I'm confident with my AI skills that if/when cheap/subsidized models go away, I'll be fine running locally. | |
| ▲ | mfro 5 hours ago | parent | prev | next [-] | | Not sure why all the other commentors are failing to mention you can spend considerably less money on an apple silicon machine to run decent local models. Fun fact: AWS offers apple silicon EC2 instances you can spin up to test. | |
| ▲ | bakugo 5 hours ago | parent | prev | next [-] | | You should be aware that any model you can run on less than $10k worth of hardware isn't going to be anywhere close to the best cloud models on any remotely complex task. Many providers out there host open weights models for cheap, try them out and see what you think before actually investing in hardware to run your own. | |
| ▲ | hleszek 5 hours ago | parent | prev | next [-] | | The latest Qwen3.6 model is very impressive for its size. Get an RTX 3090 and go to https://www.reddit.com/r/LocalLLaMA/ to see the latest news on how to run models locally. Totally fine for coding. | |
| ▲ | aray07 5 hours ago | parent | prev | next [-] | | i think the new qwen models are supposed to be good based on some the articles that i read | |
| ▲ | DeathArrow 4 hours ago | parent | prev [-] | | Unless you use H100 or 4x 5090 you won't get a decent output. The best bang for the buck now is subcribing to token plans from Z.ai (GLM 5.1), MiniMax (MiniMax M2.7) or ALibaba Cloud (Qwen 3.6 Plus) Running quantized models won't give you results comparable to Opus or GPT. |
|
|
| ▲ | epistasis 2 hours ago | parent | prev | next [-] |
| Anybody else having problem getting Opus 4.7 to write code? I had it pick up a month-old project, some small one off scripts that I want to modify, and it refused to even touch the code. So far it costs a lot less, because I'm not going to be using it. |
| |
| ▲ | apelapan an hour ago | parent | next [-] | | On the contrary, I threw a multi-threading optimization task on it, that 4.5 and 4.6 have been pretty useless at handling. 4.7 bested my hand-tuned solution by almost 2x on first attempt. This was what I thought was my best moat as a senior dev. No other model has been able to come close to the throughput I could achieve on my own before. Might be a fluke of course, and they've picked up a few patterns in training that applies to this particular problem and doesn't generalize. We'll see. | |
| ▲ | mrtesthah 2 hours ago | parent | prev [-] | | No, see, we have to leave writing code to fully identity-verified individuals working on behalf of only the largest institutions now because what if they decided to write malware? |
|
|
| ▲ | khalic 5 hours ago | parent | prev | next [-] |
| Just hit my quota with 20x for the first time today… |
|
| ▲ | avereveard 3 hours ago | parent | prev | next [-] |
| Well yeah it was disclosed here https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-... high is the new xhigh |
|
| ▲ | motbus3 3 hours ago | parent | prev | next [-] |
| I've been using 4.6 models since each of them launched.
Same for 4.5. 4.6 performers worse or the same in most of the tasks I have.
If there is a parameter that made me use 4.6 more frequently is because 4.5 get dumber and not because 4.6 seemed smarter. |
|
| ▲ | ndom91 5 hours ago | parent | prev | next [-] |
| `/model claude-opus-4-6` |
|
| ▲ | curioussquirrel 6 hours ago | parent | prev | next [-] |
| Claude's tokenizers have actually been getting less efficient over the years (I think we're at the third iteration at the least since Sonnet 3.5). And if you prompt the LLM in a language other than English, or if your users prompt it or generate content in other languages, the costs go higher even more. And I mean hundreds of percent more for languages with complex scripts like Tamil or Japanese. If you're interested in the research we did comparing tokenizers of several SOTA models in multiple languages, just hit me up. |
| |
| ▲ | arcanemachiner 5 hours ago | parent [-] | | I would encourage you to post a link here, and also to submit to HN if you haven't already. :) | | |
|
|
| ▲ | redml 4 hours ago | parent | prev | next [-] |
| It does cost more but I found the quality of output much higher. I prefer it over the dumbing of effort/models they were doing for the last two months. They have to get users used to picking the appropriate model for their task (or have an automatic mode - but still let me force it to a model). |
|
| ▲ | rafram 6 hours ago | parent | prev | next [-] |
| Pretty funny that this article was clearly written by Claude. |
|
| ▲ | DiscourseFan 4 hours ago | parent | prev | next [-] |
| Yeah I noticed today, I had it work up a spreadsheet for me and I only got 3 or 4 turns in the conversation before it used up all my (pro) credits. It wasn't even super-complicated or anything, only moderately so. |
|
| ▲ | outlore 2 hours ago | parent | prev | next [-] |
| I can manage session cost effectively myself if forking and rewinds were first class features |
|
| ▲ | chakintosh 2 hours ago | parent | prev | next [-] |
| Yeah one PRD request of a small scope app cost me 70% |
|
| ▲ | kburman 4 hours ago | parent | prev | next [-] |
| Anthropic must be loving it. It's free money. |
|
| ▲ | lacoolj 6 hours ago | parent | prev | next [-] |
| This is probably an adjacent result of this (from anthropic launch post): > In Claude Code, we’ve raised the default effort level to xhigh for all plans. Try changing your effort level and see what results you get |
| |
| ▲ | aray07 5 hours ago | parent [-] | | effort level is separate from tokenization. Tokenization impacts you the same regardless. I find 5 thinking levels to be super confusing - I dont really get why they went from 3 -> 5 |
|
|
| ▲ | aliljet 5 hours ago | parent | prev | next [-] |
| This is the reality I'm seeing too. Does this mean that the subscriptions (5x, 10x, 20x) are essentially reduced in token-count by 20-30%? |
| |
| ▲ | cbg0 3 hours ago | parent | next [-] | | Boris said on Twitter that they've increased rate limits for everyone. | |
| ▲ | aray07 5 hours ago | parent | prev [-] | | yeah thats the part that is unclear to me as well - if our usage capacity is now going to run out faster. | | |
| ▲ | AndyNemmity 4 hours ago | parent [-] | | The same thing I've been doing all the time, now has used up 1/3rd of my week in one day on max20. So yes, for the same tasks, usage runs out faster (currently) |
|
|
|
| ▲ | omega3 5 hours ago | parent | prev | next [-] |
| Contrary to people here who feel the price increases, reduction of subscription limits etc are the result of the Anthropic models being more expensive to run than the API & subscription revenue they generate I have a theory that Anthropic has been in the enshittification & rent seeking phase for a while in which they will attempt to extract as much money out of existing users as possible. Commercial inference providers serve Chinese models of comparable quality at 0.1x-0.25x. I think Anthropic realised that the game is up and they will not be able to hold the lead in quality forever so it's best to switch to value extraction whilst that lead is still somewhat there. |
| |
| ▲ | CharlesW 5 hours ago | parent [-] | | > Commercial inference providers serve Chinese models of comparable quality… "Comparable" is doing some heavy lifting there. Comparable to Anthropic models in 1H'25, maybe. | | |
|
|
| ▲ | markrogersjr 6 hours ago | parent | prev | next [-] |
| 4.7 one-shot rate is at least 20-30% higher for me |
| |
|
| ▲ | tornikeo an hour ago | parent | prev | next [-] |
| Good lord. Reading all these comments makes me feel so much better for dumping anthropic the first time their opus started becoming dumber (circa Month ago). It feels like most people in this thread are somehow bound to Claude, even though it is alread fully enshittfied. |
| |
| ▲ | therobots927 an hour ago | parent [-] | | Given that they haven’t even gone public yet, doesn’t that seem like putting the cart before the horse a bit? And if they’re already enshittifying it won’t be long until the other placers start doing so as well. Have we passed peak LLM intelligence and are we now watching it degrade as they fail to roll these new advanced models out to their increasing user base? Are the finances not adding up? Lots of questions. |
|
|
| ▲ | dallen33 6 hours ago | parent | prev | next [-] |
| I'm still using Sonnet 4.6 with no issues. |
| |
| ▲ | risyachka 6 hours ago | parent [-] | | How does this solve the issue? 4.6 will be disabled after one or more release like any other legacy model. | | |
|
|
| ▲ | rambojohnson 4 hours ago | parent | prev | next [-] |
| So intelligence has turned into a utility per Sam Altman et al., and now the same companies get to hike the price of accessing it by 20–30%, right as it’s becoming the backbone of how teams actually ship work. People are pushing out so much, so fast that last week’s output is already a blur. I’ve got colleagues who refuse to go back to writing any of this stuff by hand. And now maintaining that pace means absorbing arbitrary price increases, shrugged off with “we were operating at a loss anyway.” It stops being “pay to play” and starts looking more like pay just to stay in the ring, while enterprise players barely feel the hit and everyone else gets squeezed out. Market maturing my butthole... it’s obviously a dependency being priced in real time. Tech is an utter shit show right now, compounded by the disaster of the unemployment market still reeling from the overhiring of 2020. save up now and career pivot. pick up gardening. |
| |
| ▲ | wslh 4 hours ago | parent | next [-] | | > So intelligence has turned into a utility. "Utility" is close, but "energy source" may be closer. When it becomes the thing powering the pace of work itself, raising prices is less about charging for access and more about taxing dependency. | |
| ▲ | colechristensen 4 hours ago | parent | prev [-] | | Like every startup ever, they were selling it to you at a loss to compete for market share and are slowly increasing pricing. Duh. | | |
| ▲ | wslh 4 hours ago | parent [-] | | But the unique thing about AI is that the "world" is depending on it like water, oil, gas, etc. Not just a specific use case. |
|
|
|
| ▲ | varispeed 5 hours ago | parent | prev | next [-] |
| Don't forget that the model doesn't have an incentive to give right solution the first time. At least with Opus 4.6 after it got nerfed, it would go round in circles until you tell it to stop defrauding you and get to correct solution. That not always worked though. I found starting session again and again until less nerfed model was put on the request. Still all points to artificially make customer pay more. |
|
| ▲ | thibran 5 hours ago | parent | prev | next [-] |
| For me there is no point in using Claude Opus 4.7, it's too expensive since it does not do 100% of the job. Since AI can anyway only do 90% of most tasks, I can use another model and do the remaining 15-30% myself. |
|
| ▲ | dionian an hour ago | parent | prev | next [-] |
| I noticed it was compacting more aggressively which i actually like, because i was letting sessions get really long and using them uncached (parallel sessions) |
|
| ▲ | AIrtemis 3 hours ago | parent | prev | next [-] |
| here comes the rug-pull to justify the enterprise pricing... |
|
| ▲ | rbren 5 hours ago | parent | prev | next [-] |
| Good reminder to choose model-agnostic tooling! |
|
| ▲ | JohnMakin 4 hours ago | parent | prev | next [-] |
| 30% more token use, but even by their benchmarks, don't appear to have any real big successes there, and some regressions. What's the point? It doesn't do any better on the suite of obedience/compliance tests I've written for 4.6, and in some tests, got worse, despite their claim there it is better. Anecdotally, it was gobbling so many tokens on even the simplest queries I immediately shut it off and went back to 4.5. Why release this? |
|
| ▲ | therobots927 5 hours ago | parent | prev | next [-] |
| As a regular listener of Ed Zitron this comes as absolutely no surprise. Once you understand the levels of obfuscation available to anthro / OAI you will realize that they have almost certainly hit a model plateau ~1 year ago. All benchmark improvements since have come at a high compute cost. And the model used when evaluating said benchmarks is not the same model you get with your subscription. This is already becoming apparent as users are seeing quality degrade which implies that anthropic is dropping performance across the board to minimize financial losses. |
|
| ▲ | synergy20 4 hours ago | parent | prev | next [-] |
| that's what i feel, going to use codex more |
|
| ▲ | ricardobeat 5 hours ago | parent | prev | next [-] |
| I can’t stand reading this. One article. Many words. Not written by a human. Feels like LLMs are devolving into having a single, instantly recognizable and predictable writing style. |
|
| ▲ | Bingolotto 5 hours ago | parent | prev | next [-] |
| Talked to Claude earlier today and Opus 4.7 cost up to 35% more. |
|
| ▲ | encoderer 6 hours ago | parent | prev | next [-] |
| In my “repo os” we have an adversarial agent harness running gpt5.4 for plan and implementation and opus4.6 for review. This was the clear winner in the bake-off when 5.4 came out a couple months ago. Re-ran the bake-off with 4.7 authoring and… gpt5.4 still clearly winning. Same skills, same prompts, same agents.md. |
|
| ▲ | AIrtemis 3 hours ago | parent | prev | next [-] |
| here comes the rug-pull |
|
| ▲ | JimmaDaRustla 4 hours ago | parent | prev | next [-] |
| Am I dumb, or are they not explaining what level thinking they're using? We all read the Anthropic blog post yesterday - 4.7 max consumes/produces an incredible number of tokens and it's not equivalent to 4.6 max; xhigh is the new "max". |
|
| ▲ | bugsense 4 hours ago | parent | prev | next [-] |
| I would use a service like Straion.com to avoid the forths and back. It increases token consumption but I can get things right the first time. |
|
| ▲ | saltyoldman 4 hours ago | parent | prev | next [-] |
| I was sort of hoping that the peak is something like $15 per hour of vibe help (yes I know some of you burn $15 in 12milliseconds), and that you can have last year's best or the current "nano/small" model at $1 per hour. But it looks like it's just creeping up. Probably because we're paying for construction, not just inference right now. |
|
| ▲ | bcjdjsndon 6 hours ago | parent | prev | next [-] |
| Because those braniacs added 20-30% more system prompt |
|
| ▲ | socratic_weeb 2 hours ago | parent | prev | next [-] |
| This is good news. It means the bubble is popping. Bye bye VC subsidies... |
|
| ▲ | stefan_ 6 hours ago | parent | prev | next [-] |
| I don't know anything about tokens. Anthropic says Pro has "more usage*", Max has 5x or 20x "more usage*" than Pro. The link to "usage limits" says "determines how many messages you can send". Clearly no one is getting billed for tokens. |
| |
|
| ▲ | CodingJeebus 6 hours ago | parent | prev | next [-] |
| The fundamental problem with these frontier model companies is that they're incentivized to create models that burn through more tokens, full stop. It's a tale as old as capitalism: you wake up every day and choose to deliver more value to your customers or your shareholders, you cannot do both simultaneously forever. People love to throw around "this is the dumbest AI will ever be", but the corollary to that is "this is the most aligned the incentives between model providers and customers will ever be" because we're all just burning VC money for now. |
| |
| ▲ | HarHarVeryFunny 3 hours ago | parent | next [-] | | > The fundamental problem with these frontier model companies is that they're incentivized to create models that burn through more tokens That's one market segment - the high priced one, but not necessarily the most profitable one. Ferrari's 2025 income was $2B while Toyota's was $30B. Maybe a more apt comparison is Sun Microsystems vs the PC Clone market. Sun could get away with high prices until the PC Clones became so fast (coupled with the rise of Linux) that they ate Sun's market and Sun went out of business. There may be a market for niche expensive LLMs specialized for certain markets, but I'll be amazed if the mass coding market doesn't become a commodity one with the winners being the low cost providers, either in terms of API/subscriptions costs, or licensing models for companies to run on their own (on-prem or cloud) servers. | |
| ▲ | NickC25 6 hours ago | parent | prev | next [-] | | > but the corollary to that is "this is the most aligned the incentives between model providers and customers will ever be" because we're all just burning VC money for now. Please say this louder for everyone to hear. We are still at the stage where it is best for Anthropic's product to be as consumer aligned (and cost-friendly) as possible. Anthropic is loosing a lot of money. Both of those things will not be true in the near future. | |
| ▲ | BosunoB 5 hours ago | parent | prev [-] | | Their bigger incentive is to deliver the best product in the cheapest way, because there is tight competition with at least 2 other companies. I know we all love to hate on capitalism but it's actually functioning fine in this situation, and the token inflation is their attempt to provide a better product, not a worse one. |
|
|
| ▲ | mikert89 6 hours ago | parent | prev | next [-] |
| The compute is expensive, what is with this outrage? People just want free tools forever? |
| |
| ▲ | aray07 6 hours ago | parent | next [-] | | are you okay with paying more for your services without any perceived improvement in the service itself? | | | |
| ▲ | rvz 6 hours ago | parent | prev [-] | | > The compute is expensive, what is with this outrage? Gamblers (vibe-coders) at Anthropic's casino realising that their new slot machine upgrade (Claude Opus) is now taking 20%-30% more credits for every push of the spin button. Problem is, it advertises how good it is (unverified benchmarks) and has a better random number generator but it still can be rigged (made dumber) by the vendor (Anthropic). The house (Anthropic) always wins. > People just want free tools forever? Using local models are the answer to this if you want to use AI models free forever. |
|
|
| ▲ | wartywhoa23 3 hours ago | parent | prev | next [-] |
| Seeing this big crowd of people trying to persuade themselves or others that the ever growing hole in their pockets is totally justified and beneficial is pretty hilarious! |
|
| ▲ | xd1936 6 hours ago | parent | prev [-] |
| And what about with Caveman[1]? 1. https://github.com/juliusbrussee/caveman |
| |
| ▲ | brokencode 6 hours ago | parent | next [-] | | Can we have one thread about Claude without people trying to shovel Caveman? Much of the token usage is in reasoning, exploring, and code generation rather than outputs to the user. Does making Claude sound like a caveman actually move the needle on costs? I am not sure anymore whether people are serious about this. To me, caveman sounds bad and is not as easy to understand compared to normal English. | |
| ▲ | Majromax 6 hours ago | parent | prev | next [-] | | Caveman doesn't and cannot change the tokenizer, so the relative token count differences by input category will remain unchanged. | |
| ▲ | aray07 6 hours ago | parent | prev [-] | | isn’t caveman a joke? why would you use it for real work? |
|
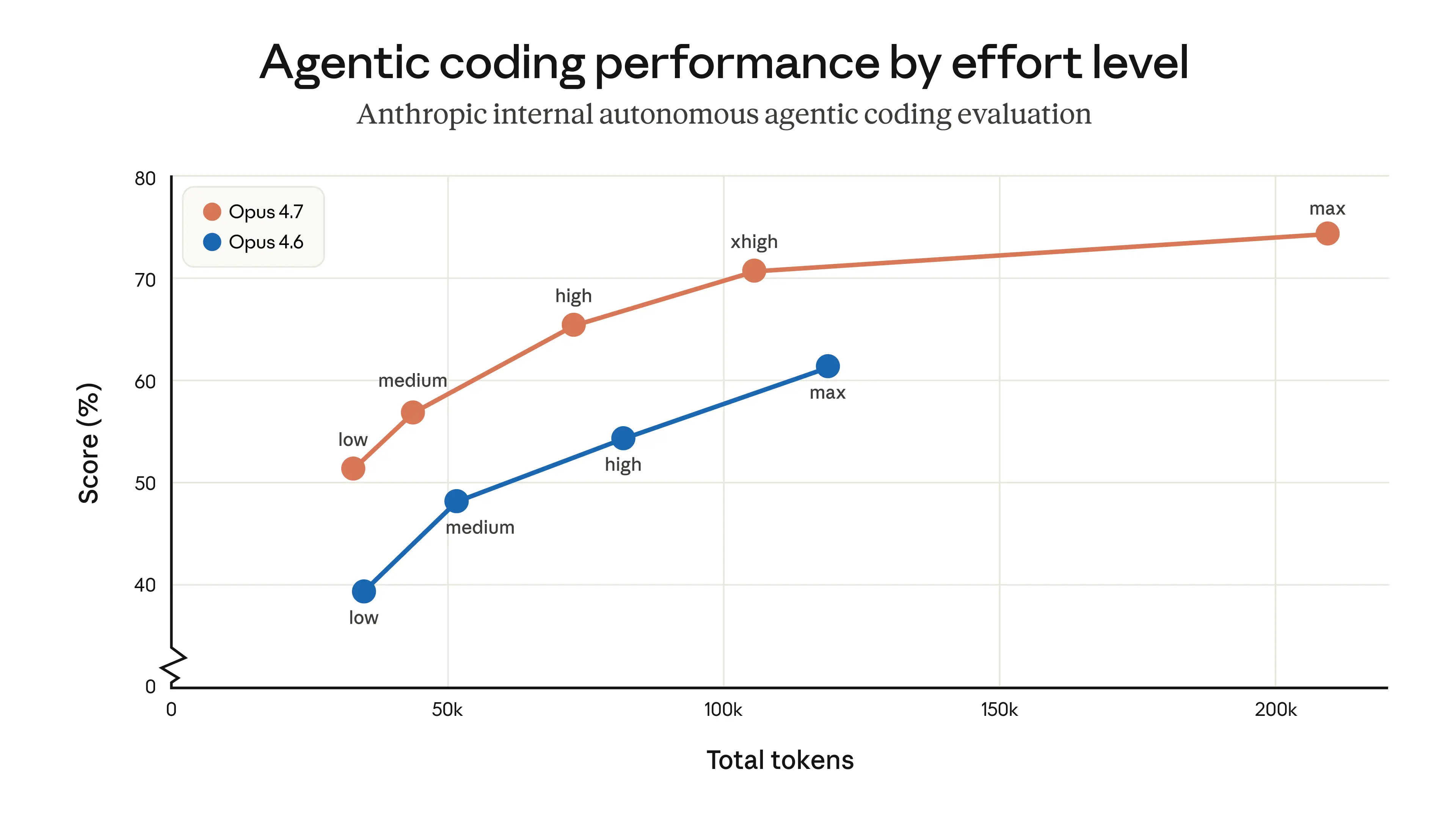{kind=link}