| ▲ | FinnLobsien 11 hours ago |
| The problem space has a few aspects: 1. We're still in the "$5 airport Uber" era of LLMs. They're heavily subsidized, and everyone still complains about costs. 2. There hasn't been a real incentive to work on cost optimization for data centers and the hardware they contain. When/if price hikes happen and send people scrambling to use other models or drastically reduce AI usage, this will suddenly need to happen. 3. We're massively overusing SOTA models. As long as you're on a subsidized subscription, you can use Claude Opus 4.8 high to write blog article meta descriptions. If you paid by token, you wouldn't do that. 4. Open models are a wildcard that could completely change the calculus. |
|
| ▲ | LUmBULtERA 10 hours ago | parent | next [-] |
| >3. We're massively overusing SOTA models. As long as you're on a subsidized subscription, you can use Claude Opus 4.8 high to write blog article meta descriptions. If you paid by token, you wouldn't do that. This idea that the subscriptions are subsidized is repeated over and over, but I've never seen any proof of this. It seems to be entirely based on the inferred API cost the subscription usage could give you, but there are a lot of assumptions needed for that to follow. |
| |
| ▲ | oarsinsync 10 hours ago | parent | next [-] | | > This idea that the subscriptions are subsidized is repeated over and over, but I've never seen any proof of this. It seems to be entirely based on the inferred API cost the subscription usage could give you, but there are a lot of assumptions needed for that to follow. My claude code environment shows me cost per token used in that session, according to API costs. It regularly exceeds $200. I pay $200 a month for my claude subscription. That's fairly obviously subsidised, unless you genuinely believe their unit costs are 100x less than what they're charging. | | |
| ▲ | LUmBULtERA 9 hours ago | parent | next [-] | | The API inference cost to customers is not the actual cost of providing inference, and the cost of providing API inference need not be the cost of providing subscriber inference. | | |
| ▲ | brandensilva 5 hours ago | parent [-] | | This is correct, they are subsidized but it's the training cost that costs the most with a majority of people hitting cache for most queries for inference. |
| |
| ▲ | qtk8 10 hours ago | parent | prev | next [-] | | But they also determine the token prices. What you describe could also be true if they take a 5x profit margin on api tokens and 2x margin on subscriptions. | |
| ▲ | Eddy_Viscosity2 8 hours ago | parent | prev | next [-] | | You're being shown the price, not the cost. | |
| ▲ | hparadiz 10 hours ago | parent | prev [-] | | That's what they want to charge you. Not the actual cost. The actual cost is a gpu that's probably already paid off and about $2 of electricity | | |
| ▲ | t-writescode 10 hours ago | parent [-] | | Most prices, like GPUs, are amortized over several years, when doing the calculus. Maybe they're already paid off, maybe they aren't. I would lean toward "aren't". | | |
|
| |
| ▲ | erfgh 10 hours ago | parent | prev | next [-] | | They are subsidized by the huge losses incurred by the AI companies. | | |
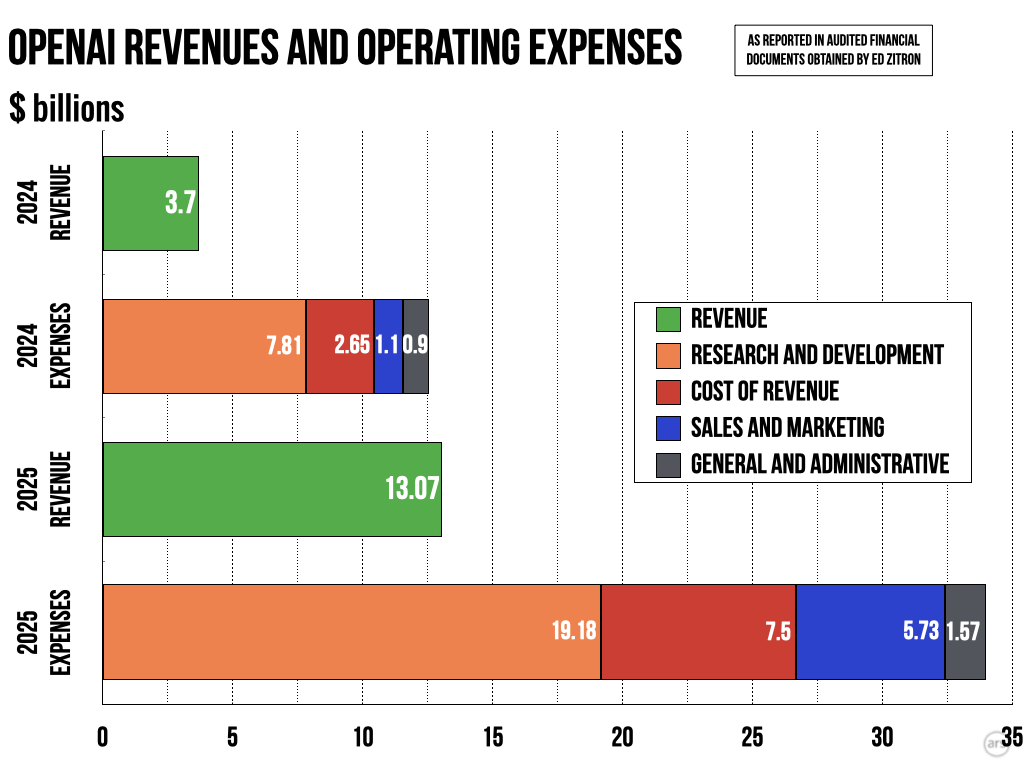
| ▲ | LUmBULtERA 9 hours ago | parent | next [-] | | Data from OpenAI shows their 2025 inference revenue exceeded their cost of inference by a good margin (https://cdn.arstechnica.net/wp-content/uploads/2026/06/opena...). Saying this is being subsidized is like saying any investment in future productive assets is "subsidized". | |
| ▲ | usef- 10 hours ago | parent | prev | next [-] | | Anthropic have claimed they expect their first profitable quarter this year. As far as we can infer their current API prices have decent margins. | | |
| ▲ | Yizahi 9 hours ago | parent [-] | | Anyone can claim they are profitable, simply by reclassifying their expenses as some other thing or shuffling them to separate corporate structure. Until we will real financial audit, the CEOs claims are just a hot air. | | |
| ▲ | usef- 9 hours ago | parent [-] | | OpenAI's leaked documents also said OpenAI was profitable on inference. The small resellers of open models have nowhere near the resources to optimise their models or inference and yet usually have a lower cost, why wouldn't the big labs? | | |
| ▲ | Yizahi 8 hours ago | parent | next [-] | | That is exactly the document I've been thinking about while writing top comment :) . Oh, our "cost of revenue" is smaller than the revenue, we are so profitable guys! If we just don't count our marketing expenses, our administrative expenses, and our unspecified losses from operations to the tune of x3 times higher than our revenue. But if we don't count them we are totally profitable guys! If we will just stop all RnD and also stop paying our salaries, support and marketing departments (and also cut 20 billion of operational losses too, whatever that is) we will earn soo soo much monies guys! | | |
| ▲ | LUmBULtERA 5 hours ago | parent [-] | | Fair to include A&G, but their marketing and training cost is about generating future growth. People say that the subscriptions are highly subsidized as if its fact -- it's certainly not a well-established fact. These people simply don't know the truth one way or another, but portray their not well supported opinion as fact. |
| |
| ▲ | rightbyte 4 hours ago | parent | prev [-] | | The leak really doesn't say that. We have no way of knowing what posts are in the different categories. |
|
|
| |
| ▲ | chilmers 10 hours ago | parent | prev | next [-] | | Only if those losses are coming from subscriptions, instead of capex and training, which is not at all clear. | | |
| ▲ | smokedetector1 10 hours ago | parent | next [-] | | this argument assumes that capex and training costs will go down over time. but theyll have to keep up with one another and stay on top of latest knowledge so Im not sure if thats true | |
| ▲ | Yizahi 9 hours ago | parent | prev | next [-] | | "Our 2015 car models are totally profitable if we will just stop making new cars and continue producing only 2015 models for the next decade." | |
| ▲ | Hamuko 10 hours ago | parent | prev [-] | | I don't understand this argument. How does it make the subscription any less subsidised if the losses are only because developing the product is just so darn expensive? Feels like arguing that it's not clear if Bugatti's losses came from selling the Veyron instead of designing and developing the Veyron. | | |
| ▲ | fragmede 10 hours ago | parent [-] | | The equivalent is when Amazon was running a loss because they were spending all their money on building warehouses. It exactly make sense, but that's the argument. | | |
| ▲ | g-b-r 8 hours ago | parent [-] | | How often does Amazon have to rebuild their warehouses? |
|
|
| |
| ▲ | winternewt 10 hours ago | parent | prev [-] | | From the article: > What is happening here is that leading AI labs are charging not only for inference but also for research in model architecture, training data collection and curation, model training cost (which can be tens or even hundreds of millions of dollars), paying their employees and recovering the marketing costs. That's what's being subsidized. | | |
| ▲ | yreg 10 hours ago | parent | next [-] | | You are saying it as if those costs were not necessary to provide the service. | | |
| ▲ | LUmBULtERA 9 hours ago | parent | next [-] | | OpenAI inference revenue exceeds its cost of inference by a good margin in 2025 (https://cdn.arstechnica.net/wp-content/uploads/2026/06/opena...) | | |
| ▲ | jijijijij 9 hours ago | parent [-] | | Great, but that's only a part of operational costs. A craftsman's revenue may exceed the electricity bill for the power drill, doesn't mean the business is sustainable. | | |
| ▲ | LUmBULtERA 9 hours ago | parent [-] | | Day 2 the craftsman has not made up for the investment/loss of their equipment. Not a useful example. | | |
| ▲ | jijijijij 8 hours ago | parent [-] | | Sorry, I don't understand what you are trying to say. | | |
| ▲ | LUmBULtERA 8 hours ago | parent [-] | | The craftsman, who may otherwise be profitable, also has investment costs that cause them to show a loss for some time. | | |
| ▲ | jijijijij 5 hours ago | parent [-] | | "Otherwise". If the craftsman revenue isn't enough to recover the investment expenses, the business is operating at loss. But that's beside the point, because research investments are not the issue at hand. As said before: Interference costs are not the only operational costs. Same as electricity costs for the craftsman. Running a power drill is not the the whole expense to consider. The craftsman has to eat, AI company's employees have to eat. The craftsman has to learn about new building standards, the AI company has to train their models because no one wants to use a product stuck in time (that's not "research", just maintenance). If not even interference was recovered in revenue, nobody would even start to argue about sustainability. I can't debate this further, because HN is rate limiting my account for dissenting opinions in the past. |
|
|
|
|
| |
| ▲ | Paradigma11 9 hours ago | parent | prev [-] | | They are not. They are necessary for the development of future models, which does not influence the availability of the current ones. Plus you have chinese models distilling current SOTA for pennies on the dollar, so as a consumer I never will be worse off in the long (1-2 years) run. |
| |
| ▲ | jijijijij 9 hours ago | parent | prev [-] | | Is this supposed to be some sort of gotcha? Apart from research and marketing, that's operational costs. I mean, every product could be cheaper, if you didn't have to pay for employees and means of production. |
|
| |
| ▲ | heyoni 10 hours ago | parent | prev | next [-] | | What assumptions are needed for inferring cost based on api pricing? | | |
| ▲ | xboxnolifes an hour ago | parent | next [-] | | API prices are consumer prices, not costs. | |
| ▲ | LUmBULtERA 9 hours ago | parent | prev | next [-] | | The API inference cost to customers is not the actual cost of providing inference, and the cost of providing API inference need not be the cost of providing subscriber inference. | |
| ▲ | gck1 10 hours ago | parent | prev [-] | | That API pricing isn't massively inflated. |
| |
| ▲ | player1234 10 hours ago | parent | prev [-] | | [dead] |
|
|
| ▲ | edb_123 10 hours ago | parent | prev | next [-] |
| > 1. We're still in the "$5 airport Uber" era of LLMs. They're heavily subsidized, and everyone still complains about costs. How does that figure look if you count in the current unprecedented LLM/AI-driven price inflation on both hardware, services and software? I don't believe we're exactly in the "$5 airport uber" era if you count that into your total. |
| |
| ▲ | nDRDY 10 hours ago | parent | next [-] | | To draw a parallel - airport Ubers are still $5, but you can't buy a 2nd hand prius any more! | | |
| ▲ | edb_123 9 hours ago | parent [-] | | Following your parallel: Except the fact that you still need a car in your life, even if you take an uber to the airport when needed :) And in this analogy you need to spend a lot more when buying a car, no matter if it's a new or 2nd hand one, following the price inflation caused by cheap Ubers. So in essence, my question is how much have those cheap Uber rides then cost you in reality, when factoring in the directly related price increases for the things you need and buy? Is it a net positive or negative at the end of the day for anyone other than the very few at the very top of the system? |
| |
| ▲ | hirako2000 10 hours ago | parent | prev | next [-] | | It's just making a parallel. We may be at the 10cent Uber. But oil and labour costs tend to go up, tokens as used today will probably cost what they cost today or less. But we won't just go to the airport, if we can go to Mars we will ask for it. | |
| ▲ | rimliu 10 hours ago | parent | prev [-] | | It about what you pay, not about what it costs. |
|
|
| ▲ | eru 11 hours ago | parent | prev | next [-] |
| Mostly agreed, however I'm not sure about 3: I suspect it works like gym memberships, and the companies mostly make their money from people who don't use the subscriptions all that much. |
| |
| ▲ | FinnLobsien 11 hours ago | parent | next [-] | | I think the problem is that the companies mostly don't make money, period. They may have better unit economics on underused subscriptions, but I don't see a world in which OAI/Anthropic don't heavily tighten the screws in the future. Right now it's silly to default to frontier models, but it won't bankrupt your company. I believe in the short-medium term future, we'll need to be more deliberate about model choices. In the long-term, of course, tech costs tend to plummet. Is there a future where in 15 years, my Apple Watch locally runs an Opus 4.8-class model? Maybe. And that would obviate this whole discussion. | | |
| ▲ | hparadiz 9 hours ago | parent [-] | | I'm just here so I can look at my post history and have a hearty laugh about in a few years. | | |
| ▲ | piva00 8 hours ago | parent [-] | | You can save it to your favourites, no need to comment at all if it's not going to add to the conversation. | | |
| ▲ | hparadiz 7 hours ago | parent [-] | | Okay here is my adding to the conversation: The current discourse about LLMs in coding especially is based on the cheapest type of inference: text. This technology was designed for images which is a much more computationally expensive task than text. If it's already profitable to use this technology for multimedia like images and videos then using it on a text based inference for code is less then 1% as computationally expensive. Furthermore in the aggregate over time the computational expensive of text based inference precipitates negatively. In other words using it to write code will inevitably become a throwaway computational task like decompressing a jpeg. And yes decompressing jpegs would lag your 386 in the early 90s. | | |
| ▲ | piva00 6 hours ago | parent [-] | | What? LLMs were designed for text, it's in their name "large language model". Only with specialised encoders like vision transformers they were able to process images as well but you're absolutely wrong about the original design intent. In the end you just added misinformation, just save the comment to your favourites and set a reminder to check it again in a few years like you wanted. | | |
| ▲ | hparadiz 6 hours ago | parent [-] | | The first technological breakthroughs were with face and red eye detection in 2003. Then object detection between 2008-2012. Text models didn't become useful until about 2016. Please watch the first course of Dr Fei Fei Li's lectures on the subject. | | |
| ▲ | piva00 3 hours ago | parent [-] | | If we want to keep tracing the lineage of AI we'll have to go all the way back to Markov chains from the 70s. You said LLMs were designed for images which is absolutely incorrect. |
|
|
|
|
|
| |
| ▲ | Cthulhu_ 10 hours ago | parent | prev | next [-] | | I'd say that is/was their long game, but it's still very much in hype phase so there's a lot of people intensively using these models, and I don't think it's anywhere near cost efficient right now. Maybe in the long run when people get bored with it, but on the other hand people are becoming dependent on it for everyday things. We've already seen price hikes / token limits earlier this year, with suddenly some people running out of budget on the first day of the month. This will likely keep going for a while. On the other hand, costs will drop too - open models and specialized hardware, as the article notes. The long question will be whether the companies will get a return on their invested billions. I don't think they will, not with the amount of competition they're facing, and I don't think any one company or model (series) has a monopoly yet. Popularity sure, but I'm confident a competitor may appear tomorrow and people will switch. | |
| ▲ | iamacyborg 11 hours ago | parent | prev | next [-] | | I follow a guy called Daniel McCarthy on LinkedIn who writes a lot on CLV and that seems to be his take. Even if theoretically you get way more than you pay with subscriptions, the vast majority of people are not power users. https://danielminhmccarthy.com/ | | |
| ▲ | dofm 11 hours ago | parent [-] | | The vast majority of active users of ChatGPT could successfully use a model like Gemma 4 12B with agentic search if x86 hardware didn't make that so difficult. Likely even the E4B, which is really both fun and impressive. That is clearly a big component of Apple's bet, anyway. | | |
| ▲ | avadodin 10 hours ago | parent [-] | | I have experimented with it and E4b is perfectly capable of being useful if you provide it with ready–to–use skills. It's still more like programming than telling a chatbot to go make you GTAVI in JavaScript and make sure the graphics are as good as the original. Maybe a safer prediction would be that most people will be fine just using hybrid agentic programs that run the models locally(probably with extra spyware). I think this is Apple's bet. |
|
| |
| ▲ | xienze 10 hours ago | parent | prev | next [-] | | > I suspect it works like gym memberships, and the companies mostly make their money from people who don't use the subscriptions all that much. I think it's like that, but not quite. The people who have a subscription but barely use it were probably never doing any serious work with AI in the first place. I.e., why would they get a subscription when their one or two chat questions (or, "make a picture of me as a superhero" prompts) per day can be had for free? Especially with Claude, I think people who subscribe skew very heavily towards people that can very easily make more than $20 worth of queries in a month. And then there's the not-insignificant number of people who are tokenmaxxing. It's like the gym membership model except ten percent of members are able to spend 72 hours per day at the gym while the rest spend 8 IMO. | | |
| ▲ | usef- 9 hours ago | parent [-] | | Based on the people I know, they're paying because when ask they want the smartest model to be the one answering. There's still quite a difference between models. |
| |
| ▲ | PunchyHamster 10 hours ago | parent | prev [-] | | Technically yes but it's not hard to get to $20 plan caps. Till current hardware prices cool down I don't see it being easy to make money on frontier models. |
|
|
| ▲ | jstummbillig 10 hours ago | parent | prev | next [-] |
| > We're still in the "$5 airport Uber" era of LLMs. They're heavily subsidized, and everyone still complains about costs. Inference is not exactly cheap. Based on what do you think this is "heavily subsidized" still? What would to token cost have to be, with current models, for it to not be that? What do you know that has you make such a claim? |
|
| ▲ | fragmede 9 hours ago | parent | prev | next [-] |
| > 1. We're still in the "$5 airport Uber" era of LLMs. They're heavily subsidized, and everyone still complains about costs. Do they? It's free right now at chat.com. After that it's $20/month which isn't much in the US. Three Starbucks or two meals at McDonald's will run you more than that these days. |
|
| ▲ | PunchyHamster 10 hours ago | parent | prev [-] |
| > 2. There hasn't been a real incentive to work on cost optimization for data centers and the hardware they contain. When/if price hikes happen and send people scrambling to use other models or drastically reduce AI usage, this will suddenly need to happen. It's actually worse, the AI explosion just hikes hardware prices faster than capacity can catch up - and it will likely not catch up in a while because investments are both expensive, long, and might not seem all that good idea while bubble is still bubbling. The massive push frankly also made it unsustainable. If RAM didn't cost 3x and compute manufacturers would have to compete instead of selling every unit instantly at whatever price they want the frontier model tokens might've costed closer to sustainable amount |
{kind=link}