| ▲ | applfanboysbgon 16 hours ago |
| > Imagine instead of > Now imagine > Imagine what that would do Imagine if your grandma had wheels! She'd be a bicycle. Now imagine she had an engine. She could be a motorcycle! Unfortunately for grandma, she lives in reality and is not actually a motorcycle, which would be cool as hell. Our imagination can only take us so far. To more substantively reply to your longer linked comment: your hypothesis is that people spend as little as 10% of time coding and the other 90% of time in meetings, but that if they could code more, they wouldn't need to meet other people because they could do all the work of an entire team themselves[1]. The problem with your hypothesis is that you take for granted that LLMs actually allow people to do the work of an entire team themselves, and that it is merely bureacracy holding them back. There have been absolutely zero indicators that this is true. No productivity studies of individual developers tackling tasks show a 10x speedup; results tend to be anywhere from +20% to minus 20%. We aren't seeing amazing software being built by individual developers using LLMs. There is still only one Fabrice Bellard in the world, even though if your premise could escape the containment zone of imagination anyone should be able to be a Bellard on their own time with the help of LLMs. [1] Also, this is basically already true without LLMs. It is the reason startups are able to disrupt corporate behemoths. If you have just a small handful of people who spend the majority of their work time writing code (by hand! No LLMs required!), they can build amazing new products that outcompete products funded by trillion-dollar entities. Your observation of more coding = less meetings required in the first place has an element of truth to it, but not because LLMs are related to it in any particular way. |
|
| ▲ | sgc 15 hours ago | parent | next [-] |
| > Imagine if your grandma had wheels! She'd be a bicycle.
I always took this to be a sharp jab saying the entire village is riding your grandma, giving it a very aggressive undertone. It's pretty funny nonetheless.Too early to say what AI brings to the efficiency table I think. In some major things I do it's a 1000x speed up. In others it is more a different way of approaching a problem than a speed up. In yet others, it is a bit of an impediment. It works best when you learn to quickly recognize patterns and whether it will help. I don't know how people who are raised with ai will navigate and leverage it, which is the real long-term question (just as the difference between pre- and post-smartphone generations is a thing). |
| |
| ▲ | demorro 6 hours ago | parent [-] | | 1000x is ridiculous. What are you doing where that level of improvement is measurable. That means you are doing things that would have taken you a year of full-time work in less than half a day now. EDIT: Retracted, I think the example given below is reasonably valid. | | |
| ▲ | sgc 5 hours ago | parent [-] | | I understand, but the improvement is actually more than that. It is not directly programming, but look at this page [1] for example. I spent years handcrafting parallel texts of English and Greek and had managed to put just under 400 books online. With AI, I managed to translate and put in parallel 1500 more books very quickly. At least 2/3 of those have never been translated into English, ever. That means I have done what the entire history of English-speaking scholars has never managed to do. And the quality is good enough that I have already had publishers contacting me to use the translations. There are a couple other areas where I am getting similar speed ups, but of course this is not the norm. [1] https://catholiclibrary.org/library/browse/ | | |
| ▲ | demorro 5 hours ago | parent [-] | | ... you know what. Whilst I suspect the quality of these translations is probably not great. Fair play this is a valid example. | | |
| ▲ | sgc 5 hours ago | parent [-] | | Of course they are not perfect, but no translation is even close to perfect. The floor is actually incredibly low. All I can say is that many doctoral-level scholars, including myself and some academic publishers, find them to be somewhere between serviceable and better than average. | | |
| ▲ | applfanboysbgon 2 hours ago | parent [-] | | Knowing the quality of LLM translations between the two languages I speak, hearing it used like this by supposed academics invokes a deep despair in me. "Serviceable" is a flimsy excuse for mass-producing and publishing slop. Particularly given that slop will displace efforts to produce human translations, putting a ceiling on humanity's future output - no one will ever aspire to do better than slop, so instead of a few great translations, we'll get more slop than we would ever even want to read. I guess it does depend on the languages involved; one study suggests that it's even worse than Google Translate for some languages, but maybe actually okay at English<-->Spanish? > There were 132 sentences between the two documents. In Spanish, ChatGPT incorrectly translated 3.8% of all sentences, while GT incorrectly translated 18.1% of sentences. In Russian, ChatGPT and GT incorrectly translated 35.6% and 41.6% of all sentences, respectively. In Vietnamese, ChatGPT and GT incorrectly translated 24.2% and 10.6% of sentences, respectively. https://jmai.amegroups.org/article/view/9019/html | | |
| ▲ | sgc an hour ago | parent [-] | | I wouldn't have put it online if I didn't think it was a major improvement over nothing. Realistically, if we haven't translated it in the last 500 years, there is no point for the next several hundred years of history to stick with nothing as well. It takes a bit more than pasting sentences in chatGPT to get a serviceable translation of course, but significantly better results than that are possible. I have not tried translating into other languages, but I am sure having English as the target language is a help. It's all right there on my website in parallel text, everybody can check and come to their own conclusion rather than driving by with unhelpful generalizations. And really, that is the primary scope of these translations: as aids in reading an original text. |
|
|
|
|
|
|
|
| ▲ | keeda 15 hours ago | parent | prev | next [-] |
| > No productivity studies of individual developers tackling tasks show a 10x speedup; results tend to be anywhere from +20% to minus 20%. The only study showing a -20% came back and said, "we now think it's +9% - +38%, but we can't prove rigorously because developers don't want to work without AI anymore": https://news.ycombinator.com/item?id=47142078 Even at the time of the original study, most other rigorous studies showed -5% (for legacy projects, obsolete languages) to 30% (more typical greenfield AND brownfield projects) way back in 2024. Today I hear numbers up to 60% from reports like DX. But this is exactly missing the point. Most of them are still doing things the old way, including the very process of writing code. Which brings me to this point: > There have been absolutely zero indicators that this is true. I could tell you my personal experience, or link various comments on HN, or point you to blogs like https://ghuntley.com/real/ (which also talks about the origanizational impedance mismatch for AI), but actual code would be a better data point. So there are some open-source projects worth looking at, but they are typically dismissed because they look so weird to us. Here's two mostly vibe-coded (as in, minimal code review, apparently) projects that people shredded for having weird code, but is already used by 10s of 1000s of people, up to 11 - 18K stars now. Look at the commit volume and patterns for O(300K) LoC in a couple of months, mostly from one guy and his agent: https://github.com/steveyegge/beads/graphs/commit-activity https://github.com/steveyegge/gastown/graphs/commit-activity It's like nothing we've seen before, almost equal number of LoC additions and deletions, in the 100s of Ks! It's still not clear how this will pan out long term, but the volume of code and apparent utility (based purely on popularity) is undeniable. |
| |
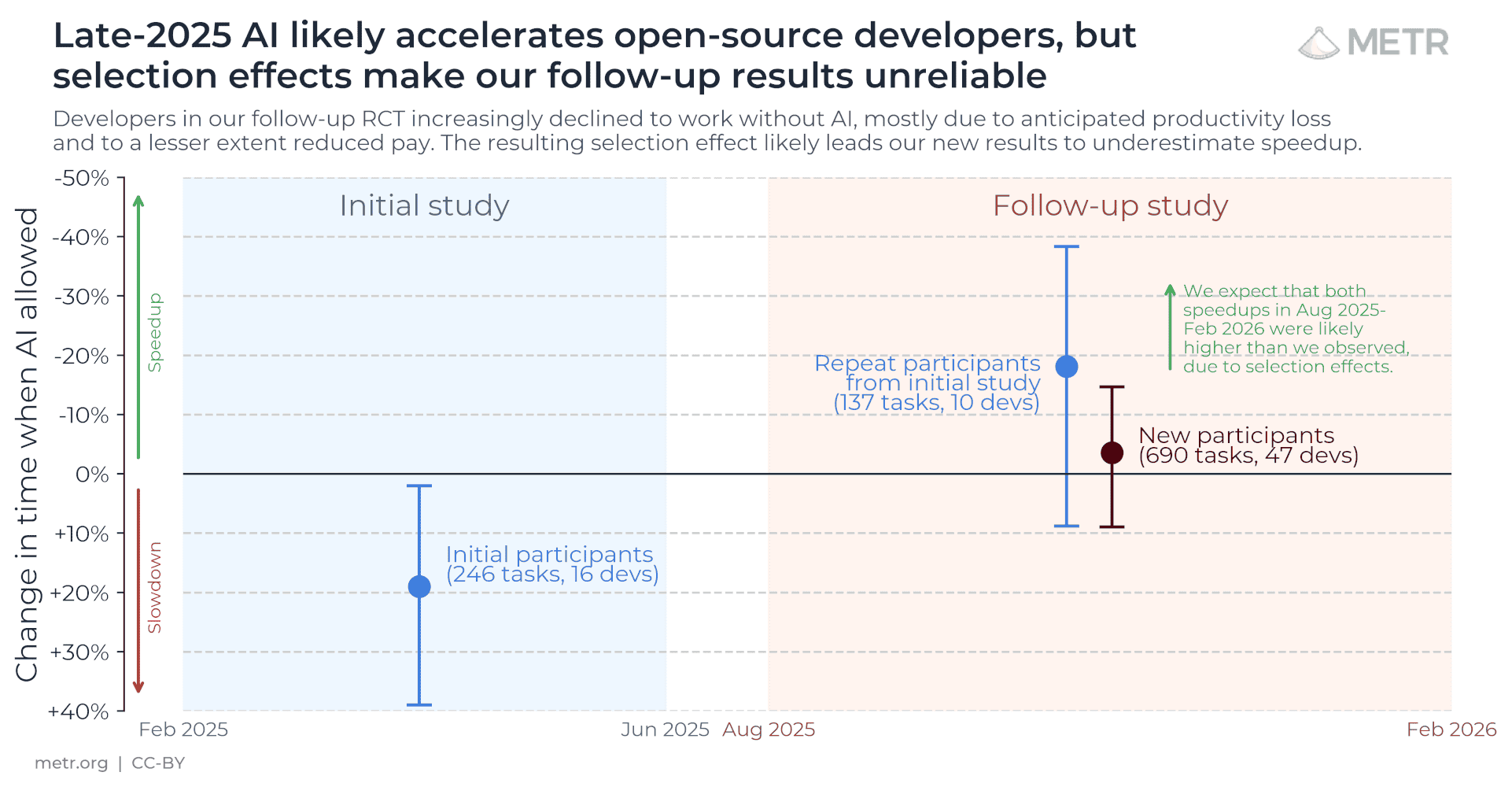
| ▲ | laserlight 7 hours ago | parent | next [-] | | > we now think it's +9% - +38% If you are referring to the following quote [0], you are off by a sign: > we now estimate a speedup of -18% with a confidence interval between -38% and +9%. [0] https://metr.org/blog/2026-02-24-uplift-update/ | | |
| ▲ | demorro 6 hours ago | parent | next [-] | | That update blog is funny. The only data they can get at reports slowdowns, but they struggle to believe it because developers self-report amazing speedups. You'd get the same sort of results if you were studying the benefits of substance abuse. "It is difficult to study the downsides of opiates because none of our participants were willing to go a day without opiates. For this reason, opiates must be really good and we're just missing something." | |
| ▲ | keeda 2 hours ago | parent | prev [-] | | My bad, I messed up by being lazy while switching from decreases in time taken (that they report) to increased in throughput. (Yes, it's not just flipping the sign, but as I said, I was being lazy!) The broad point still holds, their initial findings have been reversed, and they expect selection effects masked a higher speedup. The language is confusing, but the chart helps: https://metr.org/assets/images/uplift-2026-post/uplift_timel... |
| |
| ▲ | applfanboysbgon 14 hours ago | parent | prev [-] | | > they are typically dismissed because they look so weird to us. I dismiss them because Yegge's work (if it can even be called his work, given that he doesn't look at the code) is steaming garbage with zero real-world utility, not "because they look weird". You suggest the apparent utility is undeniable, while saying "based purely on popularity" -- but popularity is in no way a measure of utility. Yegge is a conman who profited hundreds of thousands of dollars shilling a memecoin rugpull tied to these projects. The actual thousands of users are people joining the hypetrain, looking to get in on the promised pyramid scheme of free money where AI will build the next million dollar software for you, if only you have the right combination of .md files to make it work. None of these software are actually materialising, so all the people in this bubble can do is make more AI wrappers that promise to make other AI wrappers that will totally make them money. I am completely open to being proven wrong by a vibe-coded open source application that is actually useful, but I haven't seen a single one. Literally not even one. I would count literally anything where the end-product is not an AI wrapper itself, which has tens to hundreds of thousands of users, and which was written entirely by agents. One example of that would be great. Just one. There have been a couple of attempts at a web browser, and Claude's C compiler, but neither are actually useful or have any real users; they are just proofs of concept and I have seen nothing that convinces me they are a solid foundation from which you could actually build useful software from, or that models will ever be on a trajectory to make them actually useful. | | |
| ▲ | keeda an hour ago | parent [-] | | The memecoin thing was stupid, totally. Yegge should never have touched it, because well, crypto, but also because that's a distraction from the actual project. > popularity is in no way a measure of utility Why would it be popular if it's not useful? Yegge is not like some superstar whose products are popular just because he made them. And while some people may be chasing dollars, most of them are building software that scratches an itch. (Search for Beads on GitHub, you'll find thousands of public repos, and lord knows how many private repos.) Beads has certainly made my agents much more effective, even the older models. To understand its utility you have to do agentic coding for a while, see the stupid mistakes agents make because they forget everything, and then introduce Beads and see almost all those issues melt away. > None of these software are actually materialising They are if you look for them. There are many indications (often discussed here) showing spikes in apps on app stores, number of GitHub projects, and Show HN entries. Now, you may dismiss these as "not actually useful", and at this volume that's undoubtedly true for a lot of them. But there is already early data showing growth not only in mobile app downloads, but also time spent per user and revenue -- which are pretty clear indications of utility: https://sensortower.com/blog/state-of-mobile-2026 Edit: it occurs to me that by "vibe-coding" we may be talking about two different things -- I tend to mean "heavily AI-assisted coding" whereas you likely mean "never look at the code YOLO coding." I'll totally agree that YOLO vibe-coded apps by non-experts will be crap. Other than Beads and Gastown I don't know of any such app that is non-trivial. But then those were steered by a highly experienced engineer, and my original point was, vibe-coding correctly could look very weird by today's best practices. |
|
|
|
| ▲ | pishpash 15 hours ago | parent | prev [-] |
| This isn't the counter you think it is. It's too much to expect existing behemoths to reshape their orgs substantially on a quick enough timeline. The gains will be first seen in new companies and new organizations, and they will be able to stay flat a longer and outcompete the behemoths. |
{kind=link}