| ▲ | Unrolling the Codex agent loop(openai.com) |
| 232 points by tosh 7 hours ago | 112 comments |
| |
|
| ▲ | postalcoder 4 hours ago | parent | next [-] |
| The best part about this blog post is that none of it is a surprise – Codex CLI is open source. It's nice to be able to go through the internals without having to reverse engineer it. Their communication is exceptional, too. Eric Traut (of Pyright fame) is all over the issues and PRs. https://github.com/openai/codex |
| |
| ▲ | boguscoder 5 minutes ago | parent | next [-] | | I thought Eric Traut was famous for his pioneering work in virtualization, TIL he has Pyright fame too ! | |
| ▲ | redox99 4 hours ago | parent | prev | next [-] | | For some reason a lot of people are unaware that Claude Code is proprietary. | | |
| ▲ | atonse 3 hours ago | parent | next [-] | | Probably because it doesn’t matter most of the time? | | |
| ▲ | mi_lk 3 hours ago | parent | next [-] | | Same. If you're already using a proprietary model might as well just double down | |
| ▲ | fragmede 2 hours ago | parent | prev [-] | | If the software is, say, Audacity, who's target market isn't specifically software developers, sure, but seeing as how Claude code's target market has a lot of people who can read code and write software (some of them for a living!) it becomes material. Especially when CC has numerous bugs that have gone unaddressed for months that people in their target market could fix. I mean, I have my own beliefs as to why they haven't opened it, but at the same time, it's frustrating hitting the same bugs day after day. |
| |
| ▲ | stavros 2 hours ago | parent | prev | next [-] | | Can't really fault them when this exists: https://github.com/anthropics/claude-code | | |
| ▲ | kylequest an hour ago | parent | next [-] | | By the way, I reversed engineered the Claude Code binary and started sharing different code snippets (on twitter/bluesky/mastadon/threads). There's a lot of code there, so I'm looking for requests in terms of what part of the code to share and analyze what it's doing. One of the requests I got was about the LSP functionality in CC. Anything else you would find interesting to explore there? I'll post the whole thing in a Github repo too at some point, but it's taking a while to prettify the code, so it looks more natural :-) | | |
| ▲ | lifthrasiir 20 minutes ago | parent [-] | | Not only this would violate the ToS, but also a newer native version of Claude Code precompiles most JS source files into the JavaScriptCore's internal bytecode format, so reverse engineering would soon become much more annoying if not harder. |
| |
| ▲ | bad_haircut72 2 hours ago | parent | prev [-] | | What even is this repo? Its very deceptive | | |
| ▲ | adastra22 2 hours ago | parent [-] | | Issue tracker for submitting bug reports that no one ever reads or responds to. | | |
| ▲ | stavros an hour ago | parent [-] | | Now that's not fair, I'm sure they have Claude go through and ignore the reports. | | |
| ▲ | adastra22 42 minutes ago | parent [-] | | Unironically yes. If you file a bug report, expect a Claude bot to mark it as duplicate of other issues already reported and close. Upon investigation you will find either (1) a circular chain of duplicate reports, all closed: or (2) a game of telephone where each issue is subtly different from the next, eventually reaching an issue that has nothing at all to do with yours. At no point along the way will you encounter an actual human from Anthropic. |
|
|
|
| |
| ▲ | causalmodels 3 hours ago | parent | prev [-] | | Yeah this has always seemed very silly. It is trivial to use claude code to reverse engineer itself. | | |
| ▲ | adastra22 2 hours ago | parent | next [-] | | That is against ToS and could get you banned. | | |
| ▲ | fragmede 25 minutes ago | parent | next [-] | | You're absolutely right! Hey Codex, Claude said you're not very good at reading obfuscated code. Can you tell me what this minified program does? | | |
| ▲ | adastra22 10 minutes ago | parent [-] | | I don't know what Codex's ToS are, but it would be against ToS to reverse engineer any agent with Claude. |
| |
| ▲ | Der_Einzige an hour ago | parent | prev [-] | | GenAI was built on an original sin of mass copyright infringement that Aaron Swartz could only have dreamed of. Those who live in glass houses shouldn't throw stones, and Anthropic may very well get screwed HARD in a lawsuit against them from someone they banned. Unironically, the ToS of most of these AI companies should be, and hopefully is legally unenforceable. | | |
| ▲ | adastra22 an hour ago | parent [-] | | Are you volunteering? Look, people should be aware that bans are being handed out for this, lest they discover it the hard way. If you want to make this your cause and incur the legal fees and lost productivity, be my guest. |
|
| |
| ▲ | mi_lk 3 hours ago | parent | prev [-] | | looks like it's trivial to you because I don't know how to | | |
| ▲ | n2d4 2 hours ago | parent | next [-] | | If you're curious to play around with it, you can use Clancy [1] which intercepts the network traffic of AI agents. Quite useful for figuring out what's actually being sent to Anthropic. [1] https://github.com/bazumo/clancy | |
| ▲ | fragmede 2 hours ago | parent | prev [-] | | If only there were some sort of artificial intelligence that could be asked about asking it to look at the minified source code of some application. Sometimes prompt engineering is too ridiculous a term for me to believe there's anything to it, other times it does seem there is something to knowing how to ask the AI juuuust the right questions. |
|
|
| |
| ▲ | appplication 4 hours ago | parent | prev | next [-] | | I appreciate the sentiment but I’m giving OpenAI 0 credit for anything open source, given their founding charter and how readily it was abandoned when it became clear the work could be financially exploited. | | |
| ▲ | seizethecheese an hour ago | parent [-] | | I agree that openAI should be held with a certain degree of contempt, but refusing to acknowledge anything positive they do is an interesting perspective. Why insist on a one dimensional view? It’s like a fraudster giving to charity, they can be praiseworthy in some respect while being overall contemptible, no? | | |
| ▲ | cap11235 an hour ago | parent [-] | | Why even acknowledge them in any regard? Put trash where it belongs. |
|
| |
| ▲ | frumplestlatz 4 hours ago | parent | prev [-] | | At this point I just assume Claude Code isn't OSS out of embarrassment for how poor the code actually is. I've got a $200/mo claude subscription I'm about to cancel out of frustration with just how consistently broken, slow, and annoying to use the claude CLI is. | | |
| ▲ | kordlessagain 23 minutes ago | parent | next [-] | | Yeah same with Claude Code pretty much and most people don’t realize some people use Windows. | |
| ▲ | rashidae an hour ago | parent | prev | next [-] | | Interesting. Have you tested other LLMs or CLIs as a comparison? Curious which one you’re finding more reliable than Opus 4.5 through Claude Code. | |
| ▲ | stavros 2 hours ago | parent | prev | next [-] | | OpenCode is amazing, though. | | | |
| ▲ | Razengan an hour ago | parent | prev [-] | | Anthropic/Claude's entire UX is the worst among the bunch | | |
|
|
|
| ▲ | westoncb 4 hours ago | parent | prev | next [-] |
| Interesting that compaction is done using an encrypted message that "preserves the model's latent understanding of the original conversation": > Since then, the Responses API has evolved to support a special /responses/compact endpoint (opens in a new window) that performs compaction more efficiently. It returns a list of items (opens in a new window) that can be used in place of the previous input to continue the conversation while freeing up the context window. This list includes a special type=compaction item with an opaque encrypted_content item that preserves the model’s latent understanding of the original conversation. Now, Codex automatically uses this endpoint to compact the conversation when the auto_compact_limit (opens in a new window) is exceeded. |
| |
| ▲ | icelancer 3 hours ago | parent | next [-] | | Their compaction endpoint is far and away the best in the industry. Claude's has to be dead last. | | | |
| ▲ | swalsh 2 hours ago | parent | prev | next [-] | | Is it possible to use the compactor endpoint independently? I have my own agent loop i maintain for my domain specific use case. We built a compaction system, but I imagine this is better performance. | | |
| ▲ | westoncb 2 hours ago | parent | next [-] | | I would guess you can if you're using their Responses api for inference within your agent. | |
| ▲ | __jl__ 2 hours ago | parent | prev [-] | | Yes you can and I really like it as a feature. But it ties you to OpenAI… |
| |
| ▲ | jswny 2 hours ago | parent | prev [-] | | How does this work for other models that aren’t OpenAI models | | |
| ▲ | westoncb 2 hours ago | parent [-] | | It wouldn’t work for other models if it’s encoded in a latent representation of their own models. |
|
|
|
| ▲ | jumploops 6 hours ago | parent | prev | next [-] |
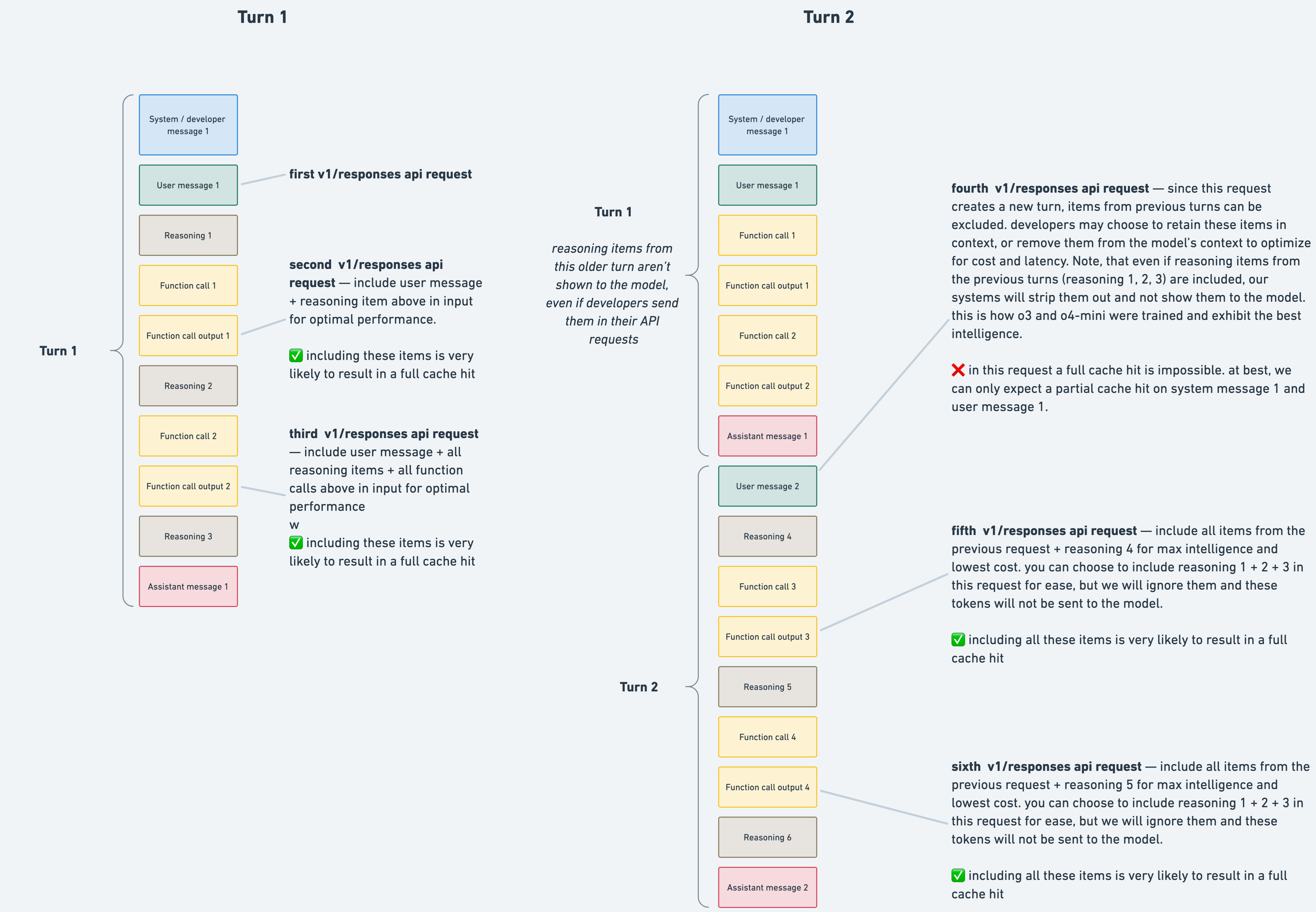
| One thing that surprised me when diving into the Codex internals was that the reasoning tokens persist during the agent tool call loop, but are discarded after every user turn. This helps preserve context over many turns, but it can also mean some context is lost between two related user turns. A strategy that's helped me here, is having the model write progress updates (along with general plans/specs/debug/etc.) to markdown files, acting as a sort of "snapshot" that works across many context windows. |
| |
| ▲ | CjHuber 5 hours ago | parent | next [-] | | It depends on the API path. Chat completions does what you describe, however isn't it legacy? I've only used codex with the responses v1 API and there it's the complete opposite. Already generated reasoning tokens even persist when you send another message (without rolling back) after cancelling turns before they have finished the thought process Also with responses v1 xhigh mode eats through the context window multiples faster than the other modes, which does check out with this. | |
| ▲ | olliepro 4 hours ago | parent | prev | next [-] | | I made a skill that reflects on past conversations via parallel headless codex sessions. Its great for context building. Repo: https://github.com/olliepro/Codex-Reflect-Skill | |
| ▲ | hedgehog 3 hours ago | parent | prev | next [-] | | This is effective and it's convenient to have all that stuff co-located with the code, but I've found it causes problems in team environments or really anywhere where you want to be able to work on multiple branches concurrently. I haven't come up with a good answer yet but I think my next experiment is to offload that stuff to a daemon with external storage, and then have a CLI client that the agent (or a human) can drive to talk to it. | | |
| ▲ | hhmc 3 hours ago | parent [-] | | git worktrees are the canonical solution | | |
| ▲ | hedgehog an hour ago | parent | next [-] | | worktrees are good but they solve a different problem. Question is, if you have a lot of agent config specific to your work on a project where do you put it? I'm coming around to the idea that checked in causes enough problems it's worth the pain to put it somewhere else. | |
| ▲ | fragmede 27 minutes ago | parent | prev [-] | | worktrees are a bunch of extra effort. if your code's well segregated, and you have the right config, you can run multiple agents in the same copy of the repo at the same time, so long as they're working on sufficiently different tasks. |
|
| |
| ▲ | dayone1 an hour ago | parent | prev | next [-] | | where do you save the progress updates in? and do you delete them afterwards or do you have like 100+ progress updates each time you have claude or codex implement a feature or change? | |
| ▲ | ljm 5 hours ago | parent | prev | next [-] | | I’ve been using agent-shell in emacs a lot and it stores transcripts of the entire interaction. It’s helped me out lot of times because I can say ‘look at the last transcript here’. It’s not the responsibility of the agent to write this transcript, it’s emacs, so I don’t have to worry about the agent forgetting to log something. It’s just writing the buffer to disk. | |
| ▲ | crorella 6 hours ago | parent | prev | next [-] | | Same here! I think it would be good if this could be made by default by the tooling. I've seen others using SQL for the same and even the proposal for a succinct way of representing this handoff data in the most compact way. | |
| ▲ | sdwr 6 hours ago | parent | prev | next [-] | | That could explain the "churn" when it gets stuck. Do you think it needs to maintain an internal state over time to keep track of longer threads, or are written notes enough to bridge the gap? | |
| ▲ | EnPissant 5 hours ago | parent | prev | next [-] | | I don't think this is true. I'm pretty sure that Codex uses reasoning.encrypted_content=true and store=false with the responses API. reasoning.encrypted_content=true - The server will return all the reasoning tokens in an encrypted blob you can pass along in the next call. Only OpenaAI can decrypt them. store=false - The server will not persist anything about the conversation on the server. Any subsequent calls must provide all context. Combined the two above options turns the responses API into a stateless one. Without these options it will still persist reasoning tokens in a agentic loop, but it will be done statefully without the client passing the reasoning along each time. | | |
| ▲ | jumploops 3 hours ago | parent [-] | | Maybe it's changed, but this is certainly how it was back in November. I would see my context window jump in size, after each user turn (i.e. from 70 to 85% remaining). Built a tool to analyze the requests, and sure enough the reasoning tokens were removed from past responses (but only between user turns). Here are the two relevant PRs [0][1]. When trying to get to the bottom of it, someone from OAI reached out and said this was expected and a limitation of the Responses API (interesting sidenote: Codex uses the Responses API, but passes the full context with every request). This is the relevant part of the docs[2]: > In turn 2, any reasoning items from turn 1 are ignored and removed, since the model does not reuse reasoning items from previous turns. [0]https://github.com/openai/codex/pull/5857 [1]https://github.com/openai/codex/pull/5986 [2]https://cookbook.openai.com/examples/responses_api/reasoning... | | |
| ▲ | EnPissant 3 hours ago | parent [-] | | Thanks. That's really interesting. That documentation certainly does say that reasoning from previous turns are dropped (a turn being an agentic loop between user messages), even if you include the encrypted content for them in the API calls. I wonder why the second PR you linked was made then. Maybe the documentation is outdated? Or maybe it's just to let the server be in complete control of what gets dropped and when, like it is when you are using responses statefully? This can be because it has changed or they may want to change it in the future. Also, codex uses a different endpoint than the API, so maybe there are some other differences? Also, this would mean that the tail of the KV cache that contains each new turn must be thrown away when the next turn starts. But I guess that's not a very big deal, as it only happens once for each turn. EDIT: This contradicts the caching documentation: https://developers.openai.com/blog/responses-api/ Specifically: > And here’s where reasoning models really shine: Responses preserves the model’s reasoning state across those turns. In Chat Completions, reasoning is dropped between calls, like the detective forgetting the clues every time they leave the room. Responses keeps the notebook open; step‑by‑step thought processes actually survive into the next turn. That shows up in benchmarks (TAUBench +5%) and in more efficient cache utilization and latency. | | |
| ▲ | jumploops 2 hours ago | parent [-] | | I think the delta may be an overloaded use of "turn"? The Responses API does preserve reasoning across multiple "agent turns", but doesn't appear to across multiple "user turns" (as of November, at least). In either case, the lack of clarity on the Responses API inner-workings isn't great. As a developer, I send all the encrypted reasoning items with the Responses API, and expect them to still matter, not get silently discarded[0]: > you can choose to include reasoning 1 + 2 + 3 in this request for ease, but we will ignore them and these tokens will not be sent to the model. [0]https://raw.githubusercontent.com/openai/openai-cookbook/mai... | | |
| ▲ | EnPissant 2 hours ago | parent [-] | | > I think the delta may be an overloaded use of "turn"? The Responses API does preserve reasoning across multiple "agent turns", but doesn't appear to across multiple "user turns" (as of November, at least). Yeah, I think you may be correct. |
|
|
|
| |
| ▲ | behnamoh 5 hours ago | parent | prev | next [-] | | but that's why I like Codex CLI, it's so bare bone and lightweight that I can build lots tools on top of it. persistent thinking tokens? let me have that using a separate file the AI writes to. the reasoning tokens we see aren't the actual tokens anyway; the model does a lot more behind the scenes but the API keeps them hidden (all providers do that). | | |
| ▲ | postalcoder 5 hours ago | parent [-] | | Codex is wicked efficient with context windows, with the tradeoff of time spent. It hurts the flow state, but overall I've found that it's the best at having long conversations/coding sessions. | | |
| ▲ | behnamoh 5 hours ago | parent [-] | | yeah it throws me out of the "flow", which I don't like. maybe the cerebras deal helps with that. | | |
| ▲ | postalcoder 5 hours ago | parent [-] | | It's worth it at the end of the day because it tends to properly scope out changes and generate complete edits, whereas I always have to bring Opus around to fix things it didn't fix or manually loop in some piece of context that it didn't find before. That said, faster inference can't come soon enough. | | |
| ▲ | behnamoh 4 hours ago | parent [-] | | > That said, faster inference can't come soon enough. why is that? technical limits? I know cerebras struggles with compute and they stopped their coding plan (sold out!). their arch also hasn't been used with large models like gpt-5.2. the largest they support (if not quantized) is glm 4.7 which is <500B params. |
|
|
|
| |
| ▲ | vmg12 6 hours ago | parent | prev [-] | | I think this explains why I'm not getting the most out of codex, I like to interrupt and respond to things i see in reasoning tokens. | | |
| ▲ | behnamoh 5 hours ago | parent [-] | | that's the main gripe I have with codex; I want better observability into what the AI is doing to stop it if I see it going down the wrong path. in CC I can see it easily and stop and steer the model. in codex, the model spends 20m only for it to do something I didn't agree on. it burns OpenAI tokens too; they could save money by supporting this feature! | | |
| ▲ | zeroxfe 5 hours ago | parent [-] | | You're in luck -- /experimetal -> enable steering. | | |
| ▲ | behnamoh 5 hours ago | parent [-] | | I first need to see real time AI thoughts before I can steer it tho! Codex hides most of them |
|
|
|
|
|
| ▲ | kordlessagain 25 minutes ago | parent | prev | next [-] |
| If anyone cares to use Codex in a nice Docker container: https://github.com/DeepBlueDynamics/codex-container |
|
| ▲ | coffeeaddict1 5 hours ago | parent | prev | next [-] |
| What I really want from Codex is checkpoints ala Copilot. There are a couple of issues [0][1] opened about on GitHub, but it doesn't seem a priority for the team. [0] https://github.com/openai/codex/issues/2788 [1] https://github.com/openai/codex/issues/3585 |
| |
| ▲ | toephu2 3 hours ago | parent | next [-] | | Gemini CLI has this | |
| ▲ | wahnfrieden 5 hours ago | parent | prev [-] | | They routinely mention in GitHub that they heavily prioritize based on "upvotes" (emoji reacts) in GitHub issues, and they close issues that don't receive many. So if you want this, please "upvote" those issues. |
|
|
| ▲ | daxfohl 2 hours ago | parent | prev | next [-] |
| I like it but wonder why it seems so slow compared to the chatgpt web interface. I still find myself more productive copying and pasting from chat much of the time. You get virtually instant feedback, and it feels far more natural when you're tossing around ideas, seeing what different approaches look like, trying to understand the details, etc. Going back to codex feels like you're waiting a lot longer for it to do the wrong thing anyway, so the feedback cycle is way slower and more frustrating. Specifically I hate when I ask a question, and it goes and starts editing code, which is pretty frequent. That said, it's great when it works. I just hope that someday it'll be as easy and snappy to chat with as the web interface, but still able to perform local tasks. |
|
| ▲ | SafeDusk 2 hours ago | parent | prev | next [-] |
| These can also be observed through OTEL telemetries. I use headless codex exec a lot, but struggles with its built-in telemetry support, which is insufficient for debugging and optimization. Thus I made codex-plus (https://github.com/aperoc/codex-plus) for myself which provides a CLI entry point that mirrors the codex exec interface but is implemented on top of the TypeScript SDK (@openai/codex-sdk). It exports the full session log to a remote OpenTelemetry collector after each run which can then be debugged and optimized through codex-plus-log-viewer. |
|
| ▲ | mkw5053 6 hours ago | parent | prev | next [-] |
| I guess nothing super surprising or new but still valuable read. I wish it was easier/native to reflect on the loop and/or histories while using agentic coding CLIs. I've found some success with an MCP that let's me query my chat histories, but I have to be very explicit about it's use. Also, like many things, continuous learning would probably solve this. |
|
| ▲ | rvnx 5 hours ago | parent | prev | next [-] |
| Codex agent loop: Call the model. If it asks for a tool, run the tool and call again (with the new result appended). Otherwise, done
https://i.ytimg.com/vi/74U04h9hQ_s/maxresdefault.jpg |
| |
| ▲ | jmkni 5 hours ago | parent [-] | | I think this should be called the Homer Simpson loop, it seems more apt | | |
|
|
| ▲ | tecoholic 5 hours ago | parent | prev | next [-] |
| I use 2 cli - Codex and Amp. Almost every time I need a quick change, Amp finishes the task in the time it takes Codex to build context. I think it’s got a lot to do with the system prompt and a the “read loop” as well, amp would read multiple files in one go and get to the task, but codex would crawl the files almost one by one. Anyone noticed this? |
| |
| ▲ | nl an hour ago | parent | next [-] | | Amp uses Gemini 3 Flash to explore code first. That's model is a great speed/intelligence trade-off especially for that use case. | |
| ▲ | sumedh 5 hours ago | parent | prev | next [-] | | Which Gpt model and reasoning level did you use in Codex and Amp? Generally I have noticed Gpt 5.2 codex is slower compared to Sonnet 4.5 in Claude Code. | | |
| ▲ | nl an hour ago | parent [-] | | Amp doesn't have a conventional model selector - you choose fast vs smart (I think that's what it is called). In smart mode it explores with Gemini Flash and writes with Opus. Opus is roughly the same speed as Codex, depending on thinking settings. |
| |
| ▲ | anukin 2 hours ago | parent | prev [-] | | What is your general flow with amp? I plan to try it out myself and have been on the fences for a while. |
|
|
| ▲ | written-beyond 6 hours ago | parent | prev | next [-] |
| Has anyone seriously used codex cli? I was using LLMs for code gen usually through the vscode codex extension, Gemini cli and Claude Code cli. The performance of all 3 of them is utter dog shit, Gemini cli just randomly breaks and starts spamming content trying to reorient itself after a while. However, I decided to try codex cli after hearing they rebuilt it from the ground up and used rust(instead of JS, not implying Rust==better). It's performance is quite literally insane, its UX is completely seamless. They even added small nice to haves like ctrl+left/right to skip your cursor to word boundaries. If you haven't I genuinely think you should give it a try you'll be very surprised. Saw Theo(yc ping labs) talk about how open ai shouldn't have wasted their time optimizing the cli and made a better model or something. I highly disagree after using it. |
| |
| ▲ | georgeven 5 hours ago | parent | next [-] | | I found codex cli to be significantly better than claude code. It follows instructions and executes the exact change I want without going off on an "adventure" like Claude code. Also the 20 dollars per month sub tier gives very generous limits of the most powerful model option (5.2 codex high). I work on SSL bio acoustic models as context. | | |
| ▲ | behnamoh 5 hours ago | parent [-] | | codex the model (not the cli) is the big thing here. I've used it in CC and w/ my claude setup, it can handle things Opus could never. it's really a secret weapon not a lot of people talk about. I'm not even using xhigh most of the time. | | |
| ▲ | copperx 5 hours ago | parent | next [-] | | When you say CC is it Codex CLI or Claude Code? | | | |
| ▲ | wahnfrieden 5 hours ago | parent | prev [-] | | No, the codex harness is also optimized for the codex models. Highly recommend using first-party OpenAI harnesses for codex. | | |
| ▲ | behnamoh 5 hours ago | parent [-] | | I used that too, but CC currently has features like hooks that codex team has refused to add far too many times. | | |
|
|
| |
| ▲ | ewoodrich 6 hours ago | parent | prev | next [-] | | OpenCode also has an extremely fast and reliable UI compared to the other CLIs. I’ve been using Codex more lately since I’m cancelling my Claude Pro plan and it’s solid but haven’t spent nearly as much time compared to Claude Code or Gemini CLI yet. But tbh OpenAI openly supporting OpenCode is the bigger draw for me on the plan but do want to spend more time with native Codex as a base of comparison against OpenCode when using the same model. I’m just happy to have so many competitive options, for now at least. | | |
| ▲ | behnamoh 5 hours ago | parent [-] | | Seconded. I find codex lacks only two things: - hooks (this is a big one) - better UI to show me what changes are going to be made. the second one makes a huge diff and it's the main reason I stopped using opencode (lots of other reasons too). in CC, I am shown a nice diff that I can approve/reject. in codex, the AI makes lots of changes but doesn't pin point what changes it's doing or going to make. | | |
| ▲ | nl 43 minutes ago | parent | next [-] | | I think Codex is probably marginally stronger than Opus in my testing. But it's much much worse at writing issues than Claude models. | |
| ▲ | written-beyond 5 hours ago | parent | prev | next [-] | | Yeah it's really weird with automatically making changes. I read in it's chain of thought that it's going to request approval for something from the user, the next message was approval granted doing it. Very weird... | |
| ▲ | zoho_seni 4 hours ago | parent | prev [-] | | You can't see diffs in git? How you using hooks? |
|
| |
| ▲ | williamstein 6 hours ago | parent | prev | next [-] | | I strongly agree. The memory and cpu usage
of codex-cli is also extremely good. That codex-cli is open source is also valuable because you can easily get definitive answers to any questions about its behavior. I also was annoyed by Theo saying that. | |
| ▲ | estimator7292 5 hours ago | parent | prev | next [-] | | It's pretty good, yeah. I get coherent results >95% of the time (on well-known problems). However, it seems to really only be good at coding tasks. Anything even slightly out of the ordinary, like planning dialogue and plot lines it almost immediately starts producing garbage. I did get it stuck in a loop the other day. I half-assed a git rebase and asked codex to fix it. It did eventually resolve all debased commits, but it just kept going. I don't really know what it was doing, I think it made up some directive after the rebase completed and it just kept chugging until I pulled the plug. The only other tool I've tried is Aider, which I have found to be nearly worthless garbage | |
| ▲ | CuriouslyC 5 hours ago | parent | prev | next [-] | | The problem with codex right now is it doesn't have hook support. It's hard to understate how big of a deal hooks are, the Ralph loop that the newer folks are losing their shit over is like the level 0, most rudimentary use of hooks. I have a tool that reduces agent token consumption by 30%, and it's only viable because I can hook the harness and catch agents being stupid, then prompt them to be smarter on the fly. More at https://sibylline.dev/articles/2026-01-22-scribe-swebench-be... | |
| ▲ | procinct 6 hours ago | parent | prev [-] | | Same goes for Claude Code. Literally has vim bindings for editing prompts if you want them. | | |
| ▲ | AlexCoventry 39 minutes ago | parent | next [-] | | Codex has Ctrl-G to start an $EDITOR of your choice, FWIW. | |
| ▲ | behnamoh 5 hours ago | parent | prev [-] | | CC is the clunkiest PoS software I've ever used in terminal; feels like it was vibe coded and anthroshit doesn't give a shit | | |
| ▲ | estimator7292 5 hours ago | parent [-] | | All of these agentic UIs are vibe coded. They advertise the percent of AI written code in the tool. | | |
| ▲ | behnamoh 5 hours ago | parent [-] | | which begs the question: which came first—agentic AI tools or the AI that vibe coded them? |
|
|
|
|
|
| ▲ | dfajgljsldkjag 6 hours ago | parent | prev | next [-] |
| The best part about this is how the program acts like a human who is learning by doing. It is not trying to be perfect on the first try, it is just trying to make progress by looking at the results. I think this method is going to make computers much more helpful because they can now handle the messy parts of solving a problem. |
|
| ▲ | mohsen1 4 hours ago | parent | prev | next [-] |
| Tool call during thinking is something similar to this I am guessing. Deepseek has a paper on this. Or am I not understanding this right? |
|
| ▲ | I_am_tiberius 4 hours ago | parent | prev | next [-] |
| Pity it doesn't support other llms. |
| |
| ▲ | evilduck 3 hours ago | parent [-] | | It does, it's just a bit annoying. I have this set up as a shell script (or you could make it an alias): codex --config model="gpt-oss-120b" --config model_provider=custom
with ~/.codex/config.toml containing: [model_providers.custom]
name = "Llama-swap Local Service"
base_url = "http://localhost:8080/v1"
http_headers = { "Authorization" = "Bearer sk-123456789" }
wire_api = "chat"
# Default model configuration
model = "gpt-oss-120b"
model_provider = "custom"
https://developers.openai.com/codex/config-advanced#custom-m... |
|
|
| ▲ | MultifokalHirn 6 hours ago | parent | prev | next [-] |
| thx :) |
|
| ▲ | ppeetteerr 5 hours ago | parent | prev [-] |
| I asked Claude to summarize the article and it was blocked haha. Fortunately, I have the Claude plugin in chrome installed and it used the plugin to read the contents of the page. |
| |
| ▲ | sdwvit 5 hours ago | parent [-] | | Great achievement. What did you learn? | | |
| ▲ | ppeetteerr 5 hours ago | parent [-] | | Nothing particularly insightful other than avoiding messing with previous messages so as not to mess with the cache. | | |
| ▲ | rvnx 5 hours ago | parent [-] | | Summary by Claude: Codex works by repeatedly sending a growing prompt to the model, executing any tool calls it requests, appending the results, and repeating until the model returns a text response
|
|
|
|
{kind=link}
{kind=link}