| ▲ | EnPissant 7 hours ago | |||||||||||||||||||||||||
I don't think this is true. I'm pretty sure that Codex uses reasoning.encrypted_content=true and store=false with the responses API. reasoning.encrypted_content=true - The server will return all the reasoning tokens in an encrypted blob you can pass along in the next call. Only OpenaAI can decrypt them. store=false - The server will not persist anything about the conversation on the server. Any subsequent calls must provide all context. Combined the two above options turns the responses API into a stateless one. Without these options it will still persist reasoning tokens in a agentic loop, but it will be done statefully without the client passing the reasoning along each time. | ||||||||||||||||||||||||||
| ▲ | jumploops 5 hours ago | parent [-] | |||||||||||||||||||||||||
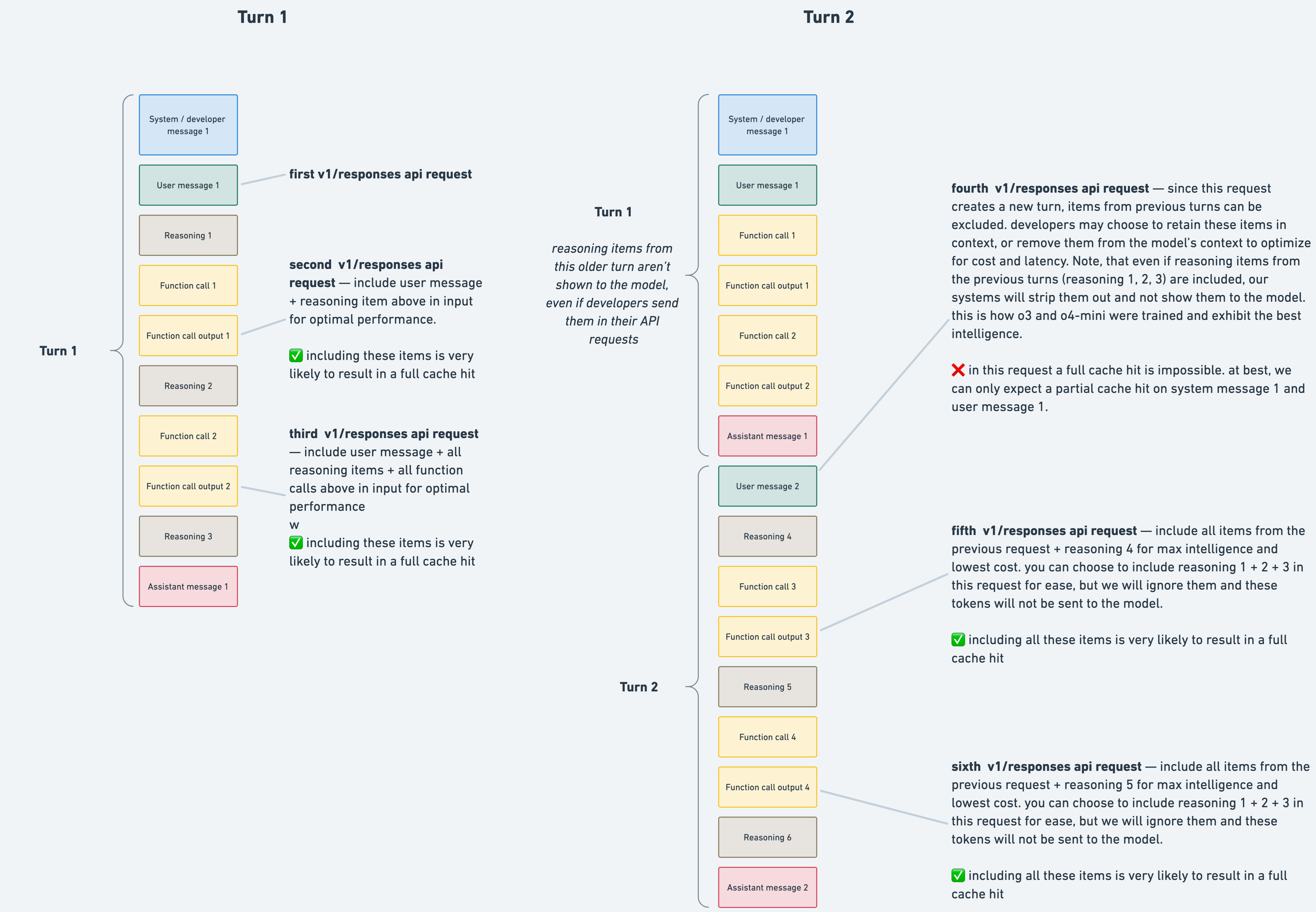
Maybe it's changed, but this is certainly how it was back in November. I would see my context window jump in size, after each user turn (i.e. from 70 to 85% remaining). Built a tool to analyze the requests, and sure enough the reasoning tokens were removed from past responses (but only between user turns). Here are the two relevant PRs [0][1]. When trying to get to the bottom of it, someone from OAI reached out and said this was expected and a limitation of the Responses API (interesting sidenote: Codex uses the Responses API, but passes the full context with every request). This is the relevant part of the docs[2]: > In turn 2, any reasoning items from turn 1 are ignored and removed, since the model does not reuse reasoning items from previous turns. [0]https://github.com/openai/codex/pull/5857 [1]https://github.com/openai/codex/pull/5986 [2]https://cookbook.openai.com/examples/responses_api/reasoning... | ||||||||||||||||||||||||||
| ||||||||||||||||||||||||||
{kind=link}