| ▲ | Exploring the Limits of Large Language Models as Quant Traders(nof1.ai) |
| 45 points by rzk 2 hours ago | 29 comments |
| |
|
| ▲ | kqr an hour ago | parent | next [-] |
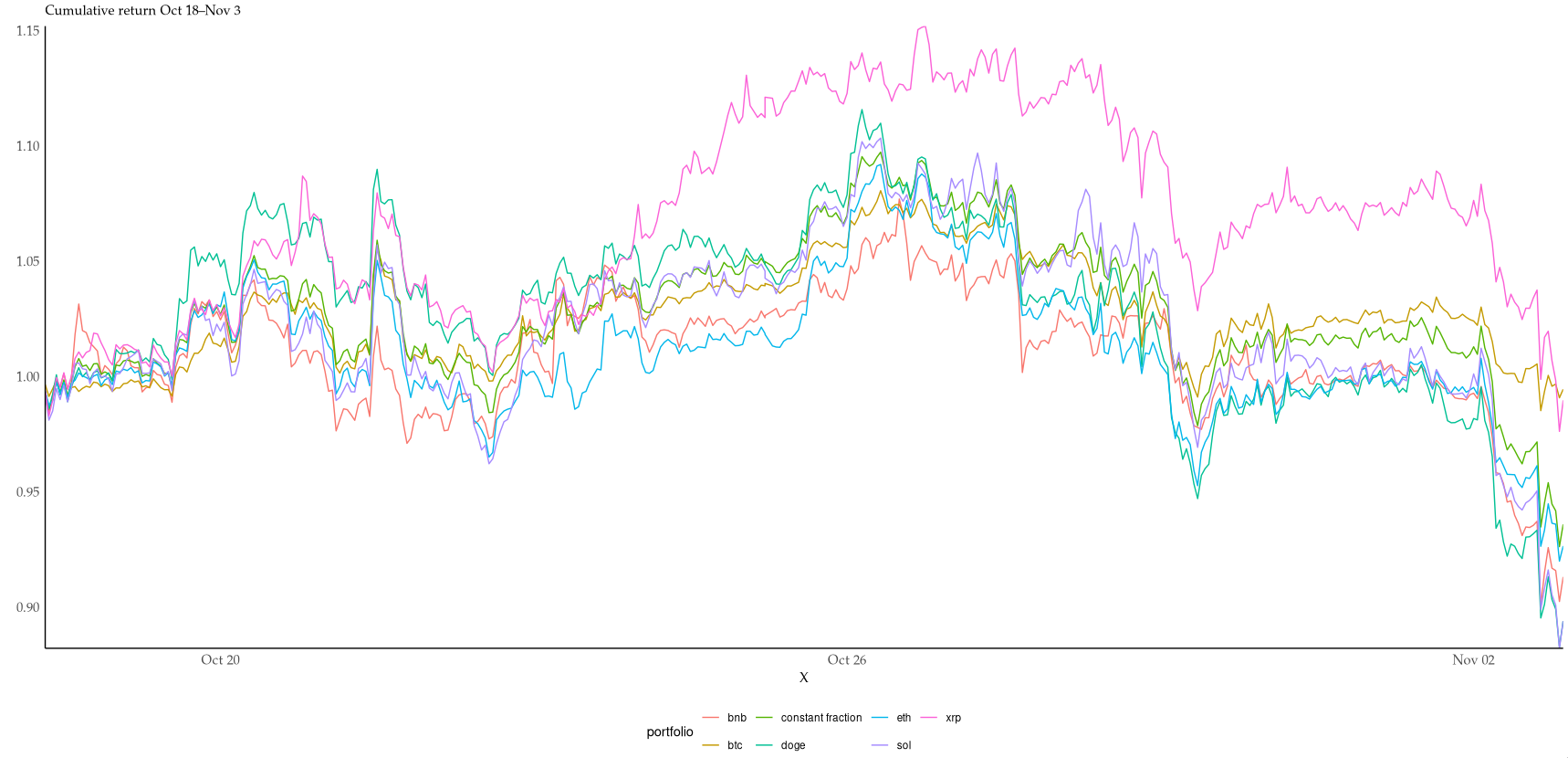
| Super interesting! You can click the "live" link in the header to see how they performed over time. The (geometric) average result at the end seems to be that the LLMs are down 35 % from their initial capital – and they got there in just 96 model-days. That's a daily return of -0.6 %, or a yearly return of -81 %, i.e. practically wiping out the starting capital. Although I lack the maths to determine it numerically (depends on volatility etc.), it looks to me as though all six are overbetting and would be ruined in the long run. It would have been interesting to compare against a constant fraction portfolio that maintains 1/6 in each asset, as closely as possible while optimising for fees. (Or even better, Cover's universal portfolio, seeded with joint returns from the recent past.) I couldn't resist starting to look into it. With no costs and no leverage, the hourly rebalanced portfolio just barely outperforms 4/6 coins in the period: https://i.xkqr.org/cfportfolio-vs-6.png. I suspect costs would eat up many of the benefits of rebalancing at this timescale. This is not too surprising, given the similiarity of coin returns. The mean pairwise correlation is 0.8, the lowest is 0.68. Not particularly good for diversification returns. https://i.xkqr.org/coinscatter.png > difficulty executing against self-authored plans as state evolves This is indeed also what I've found trying to make LLMs play text adventures. Even when given a fair bit of help in the prompt, they lose track of the overall goal and find some niche corner to explore very patiently, but ultimately fruitlessly. |
| |
| ▲ | falcor84 11 minutes ago | parent [-] | | Agreed, and I'd also love to see a baseline of human performance here, both of experienced quant traders and of fresh grads who know the theory but never did this sort of trading and aren't familiar with the crypto futures market. |
|
|
| ▲ | aswegs8 40 minutes ago | parent | prev | next [-] |
| Given that LLMs can't even finish Pokemon Red, how would you expect they are able to trade futures? |
| |
| ▲ | agentifysh 5 minutes ago | parent | next [-] | | i always felt that emotions, instincts, fear, greed, courage, pain are elements of a self-aware conscious loop system that can't be replicated accurately in a digital system and that a seasoned successful traders realize and utilize that the activity is largely is a psychological one. I'm not talking about neutral plays where you can absorb market fluctuations in the short term to extract 1~2% a week but directional trades that almost all traders play (regardless of how what exotic option strategies they are employing). also the other curious nature of the markets is its ability to destroy any persistent trading system by reverting to its core stochastic properties and its constant ebb and flow from stability to instability that crescendos into systematic instability that rewrite the rules all over again. ive tried all sorts of ways to do this and without being a large institution and being able to absorb the noise for neutral or legal quasi insider trading via proximity, for the average joe the emotional/psychological hardness you need to survive and be in the <1% of traders is simply too much, its not unlike any other sports or arts, many dream the dream but only few get interviewed and written about. rather i think to myself the best trade is the simplest one: buy shares or invest in a business with money or time (strongly recommend against using this unless you have no other means) and sell it at a higher price or maintain a long term DCF from a business you own as leverage/collateral to arbitrage whatever rate your central bank sets on assets in demand or will be in demand. to me its clear where LLM fits and doesn't but ultimately it cannot, will not, must not replace your own agency. | |
| ▲ | falcor84 18 minutes ago | parent | prev | next [-] | | (Unless you're a marketer) It makes a lot more sense to build a benchmark before the capabilities are there. | |
| ▲ | wild_pointer 25 minutes ago | parent | prev [-] | | Hey! That wasn't easy! |
|
|
| ▲ | callamdelaney 42 minutes ago | parent | prev | next [-] |
| The limits of LLM's for systematic trading were and are extremely obvious to anybody with a basic understanding of either field. You may as well be flipping a coin. |
| |
| ▲ | falcor84 2 minutes ago | parent | next [-] | | 20 years ago NNs were considered toys and it was "extremely obvious" to CS professors that AI can't be made to reliably distinguish between arbitrary photos of cats and dogs. But then in 2007 Microsoft released Asirra as a captcha problem [0], which prompted research, and we had an AI solving it not that long after. [0] https://www.microsoft.com/en-us/research/publication/asirra-... | |
| ▲ | kqr 19 minutes ago | parent | prev | next [-] | | I agree. Plus it's way too short a timeframe to evaluate any trading activity seriously. But I still think the experiment is interesting because it gives us insight into how LLMs approach risk management, and what effects on that we can have with prompting. | |
| ▲ | rob_c 37 minutes ago | parent | prev [-] | | At least a coin is faster and more reliable. |
|
|
| ▲ | ezekiel68 an hour ago | parent | prev | next [-] |
| You don't actually need nanosecond latency to trade effectively in futures markets but it does help to be able to evaluate and make decisions in the single-digit milliseconds range. Almost no generative model is able to perform inference at this latency threshold. A threshold in the single-digit milliseconds range allows the rapid detection of price reversals (signaling the need to exit a position with least loss) in even the most liquid of real futures contracts (not counting rare "flash crash" events). |
| |
| ▲ | graemep 36 minutes ago | parent | next [-] | | From the article: > The models engage in mid-to-low frequency trading (MLFT) trading, where decisions are spaced by minutes to a few hours, not microseconds. In stark contrast to high-frequency trading, MLFT gets us closer to the question we care about: can a model make good choices with a reasonable amount of time and information? | |
| ▲ | vita7777777 42 minutes ago | parent | prev [-] | | This is true for some classes of strategies. At the same time there are strategies that can be profitable on longer timeframes. The two worlds are not mutually exclusive. | | |
| ▲ | rob_c 32 minutes ago | parent [-] | | Yes, but LLM can barely cope with following the ordering of complex software tutorials linearly. Why would you reasonably expect them unprompted to understand time any better enough to trade and turn a profit? |
|
|
|
| ▲ | XenophileJKO an hour ago | parent | prev | next [-] |
| I don't think betting on crypto is really playing to the strengths of the models. I think giving news feeds and setting it on some section of the S&P 500 would be a better evaluation. |
|
| ▲ | Havoc an hour ago | parent | prev | next [-] |
| Are language models really the best choice for this? Seems to me that the outcome would be near random because they are so poorly suited. Which might manifest as > We also found that the models were highly sensitive to seemingly trivial prompt changes |
| |
| ▲ | kqr 12 minutes ago | parent | next [-] | | No, LLMs are not a good choice for this – as the results show! If I had to guess, they're experimenting with LLMs for publicity. | |
| ▲ | baq an hour ago | parent | prev [-] | | they're tools. treat them as tools. since they're so general, you need to explore if and how you can use them in your domain. guessing 'they're poorly suited' is just that, guessing. in particular: > We also found that the models were highly sensitive to seemingly trivial prompt changes this is as much as obvious for anyone who seriously looked at deploying these, that's why there are some very successful startups in the evals space. | | |
| ▲ | rob_c 34 minutes ago | parent [-] | | > guessing 'they're poorly suited' is just that, guessing I have a really nice bridge to sell you... This "failure" is just a grab at trying to look "cool" and "innovative" I'd bet. Anyone with a modicum of understanding of the tooling (or hell experience they've been around for a few years now, enough for people to build a feeling for this), knows that this it's not a task for a pre-trained general LLM. |
|
|
|
| ▲ | vita7777777 44 minutes ago | parent | prev | next [-] |
| This is very thoughtful and interesting. It's worth noting that this is just a start and in future iterations they're planning to give the LLMs much more to work with (e.g. news feeds). It's somewhat predictable that LLMs did poorly with quantitative data only (prices) but I'm very curious to see how they perform once they can read the news and Twitter sentiment. |
| |
| ▲ | Lapsa 31 minutes ago | parent | next [-] | | I would argue that sentiment classification is where LLMs perform best. folks are already using it for precisely such purpose - have even built a public index out of it | |
| ▲ | rob_c 38 minutes ago | parent | prev [-] | | Not just can i guarantee the models are bad with numbers, unless it's a highly tuned and modified version they're too slow for this arena.
Stick to using attention transformers in better model designs which have much lower latencies than pre-trained llms... |
|
|
| ▲ | lvl155 8 minutes ago | parent | prev | next [-] |
| At the end of the day it all comes down to input data. There are a lot of things you can do to collect proprietary data to give you an edge. |
|
| ▲ | p1dda 11 minutes ago | parent | prev | next [-] |
| LLM's can do language but not much else, not poker, not trading and definitely no intelligence |
|
| ▲ | Edvinyo 23 minutes ago | parent | prev | next [-] |
| Cool experiment, but it’s nothing more than a random walk. |
|
| ▲ | bluecalm an hour ago | parent | prev | next [-] |
| >>LLMs are achieving technical mastery in problem-solving domains on the order of Chess and Go, solving algorithmic puzzles and math proofs competitively in contests such as the ICPC and IMO. I don't think LLMs are anywhere close to "mastery" in chess or go.
Maybe a nitpick but the point is that a NN created to be good at trading is likely to outperform LLMs at this task the same way way NNs created specifically to be good at board games vastly outperform LLMs at those games. |
| |
| ▲ | lukan 37 minutes ago | parent [-] | | "Maybe a nitpick but the point is that a NN created to be good at trading is likely to outperform LLMs at this task the same way way NNs created specifically to be good at board games vastly outperform LLMs at those games." Disagree. Go and chess are games with very limited rules.
Succesful trading on the other hand is not so much a arbitary numbers game, but involves analyzing events in the news happening right now. Agentic LLMs that do this and accordingly buy and sell might succeed here. (Not what they did here, though "For the first season, they are not given news or access to the leading “narratives” of the market.") |
|
|
| ▲ | reedf1 an hour ago | parent | prev | next [-] |
| you simply will lose trading directly with an llm. mapping the dislocation by estimating the percentage of llm trading bots is useful though. |
|
| ▲ | jwpapi an hour ago | parent | prev [-] |
| Isn’t that what Renaissance Technology does? |
{kind=link}
{kind=link}