| ▲ | jorvi 3 days ago |
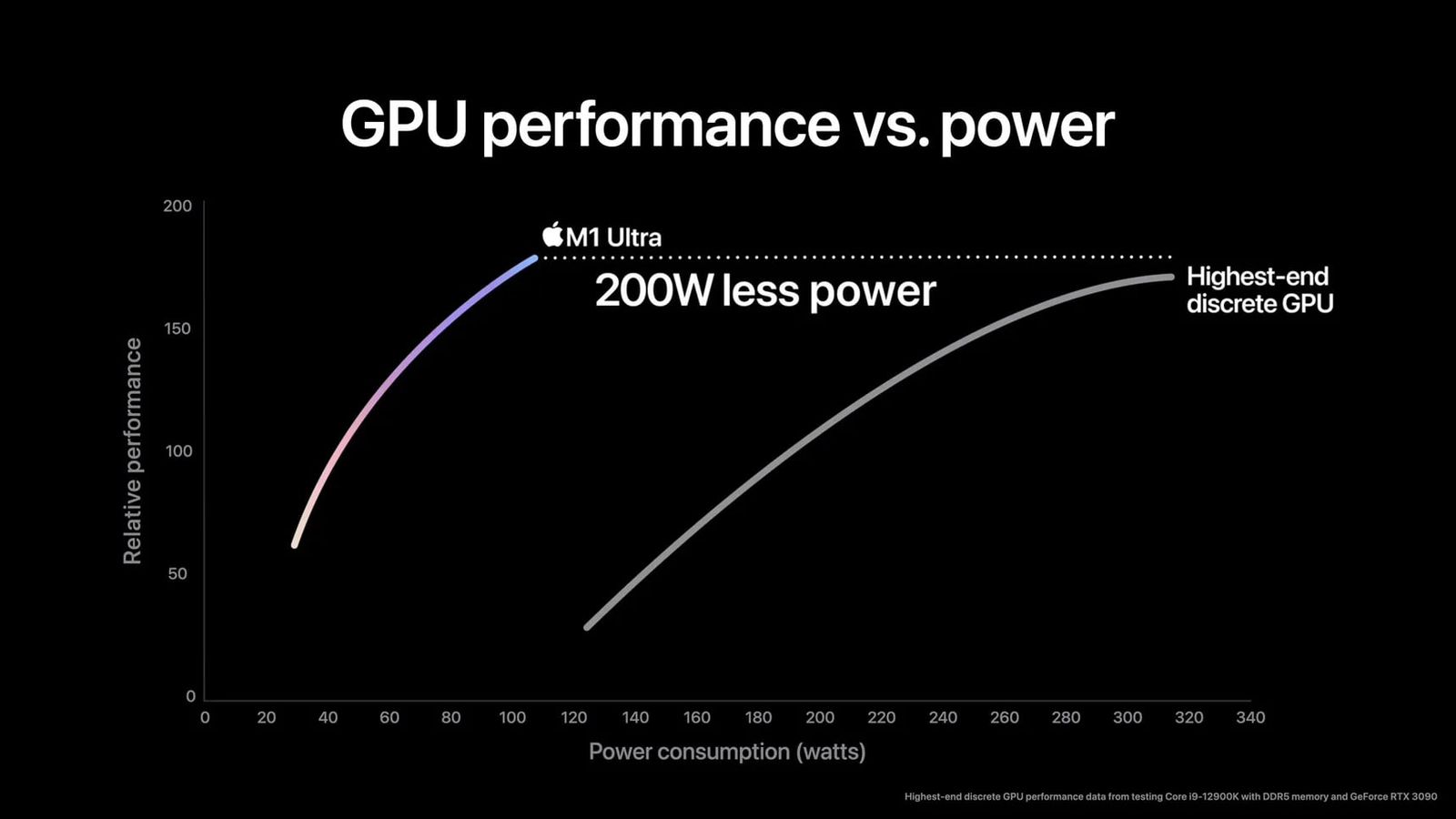
| Nice followup to your link: https://chipsandcheese.com/p/arm-or-x86-isa-doesnt-matter. Personally I do not entirely buy it. Intel and AMD have had plenty of years to catch up to Apple's M-architecture and they still aren't able to touch it in efficiency. The PC Snapdragon chips AFAIK also offer better performance-per-watt than AMD or Intel, with laptops offering them often having 10-30% longer battery life at similar performance. The same goes for GPUs, where Apple's M1 GPU completely smoked an RTX3090 in performance-per-watt, offering 320W of RTX 3090 performance in a 110W envelope: https://images.macrumors.com/t/xuN87vnxzdp_FJWcAwqFhl4IOXs=/... |
|
| ▲ | ben-schaaf 3 days ago | parent | next [-] |
| > Personally I do not entirely buy it. Intel and AMD have had plenty of years to catch up to Apple's M-architecture and they still aren't able to touch it in efficiency. The PC Snapdragon chips AFAIK also offer better performance-per-watt than AMD or Intel, with laptops offering them often having 10-30% longer battery life at similar performance. Do not conflate battery life with core efficiency. If you want to measure how efficient a CPU core is you do so under full load. The latest AMD under full load uses the same power as M1 and is faster, thus it has better performance per watt. Snapdragon Elite eats 50W under load, significantly worse than AMD. Yet both M1 and Snapdragon beat AMD on battery life tests, because battery life is mainly measured using activities where the CPU is idle the vast majority of the time. And of course the ISA is entirely irrelevant when the CPU isn't being used to begin with. > The same goes for GPUs, where Apple's M1 GPU completely smoked an RTX3090 in performance-per-watt, offering 320W of RTX 3090 performance in a 110W envelope That chart is Apple propaganda. In Geekbench 5 the RTX 3090 is 2.5x faster, in blender 3.1 it is 5x faster. See https://9to5mac.com/2022/03/31/m1-ultra-gpu-comparison-with-... and https://techjourneyman.com/blog/m1-ultra-vs-nvidia-rtx-3090/ |
| |
| ▲ | devnullbrain 3 days ago | parent | next [-] | | I want to measure the device how I use it. Race-to-sleep and power states are integral to CPU design. | | |
| ▲ | ben-schaaf 3 days ago | parent [-] | | Yes they are, but only one of those is at all affected by the choice of ISA. If modern AMD chips are better at race-to-sleep than an Apple M1 and still get worse battery life then the problem is clearly not x86-64. | | |
| ▲ | simonh 3 days ago | parent | next [-] | | Right, so as I understand it people see that x86-64 designs score poorly on a set of benchmarks and infer that it is because they are x86-64. In fact it’s because that manufacturer has made architectural choices that are not inherent to the x86-64 ISA. And that’s just hardware. MacOS gets roughly 30% better battery life on M series hardware than Asahi Linux. I’m not blaming the Asahi team, they do amazing work, they don’t even work on many of the Linux features relevant to power management, and Apple has had years of head start on preparing for and optimising for the M architecture. It’s just that software matters, a lot. So if I’m reading this right, ISA can make a difference, but it’s incremental compared to the many architectural decisions and trade offs that go into a particular design. | | |
| ▲ | bee_rider 3 days ago | parent [-] | | > So if I’m reading this right, ISA can make a difference, but it’s incremental compared to the many architectural decisions and trade offs that go into a particular design. This is true, but only in the sense that is very rarely correct to say “Factor Y can’t possibly make a difference.” |
| |
| ▲ | brookst 3 days ago | parent | prev [-] | | Does anyone care about blaming / lauding an ISA without any connection to the actual devices that people use? Performance and battery life are lived experiences. There’s probably some theoretical hyper optimization where 6502 ISA is just as good as ARM, but does it matter? | | |
| ▲ | jijijijij 3 days ago | parent [-] | | In this thread, it does. You are moving the goalpost by making this about "actual devices", when the topic is ISA efficiency. |
|
|
| |
| ▲ | fwipsy 3 days ago | parent | prev | next [-] | | > If you want to measure how efficient a CPU core is you do so under full load. Higher wattage gives diminishing returns. Chips will run higher wattage under full load just to eke out a marginal improvement in performance. Therefore efficiency improves if the manufacturer chooses to limit the chip rather than pushing it harder. Test efficiency using whatever task the chip will be used for. For most ultralight laptops, that will be web browsing etc. so the m1 MacBook/snapdragon results are valid for typical users. Maybe your workload hammers the CPU but that doesn't make it the one true benchmark. | | |
| ▲ | ben-schaaf 3 days ago | parent [-] | | No, and that's exactly the point I'm making. If you try to measure ISA efficiency using a workload where the CPU is idle the vast majority of the time, then your power usage will be dominated by things unrelated to the ISA. To further hammer the point home, let me reduce do a reductio ad absurdum: The chip is still "in use" when its asleep. Sleeping your laptop is a typical usecase. Therefore how much power is used while sleeping is a good measure of ISA efficiency. This is of course absurd because the CPU cores are entirely turned off when sleeping, they could draw 1kW with potato performance and nothing in this measurement would change. | | |
| ▲ | fwipsy a day ago | parent [-] | | You're not taking into account dynamic clock speeds, just "idle" and "load." Most CPUs have configurable TDP, and if you give them more power they will run more cores at a higher frequency. Suppose I measured the same laptop CPU under "full load" in two different computers at full load, but one is configured for a 30w TDP and the other is configured for a 40w TDP. The first PC will be more efficient, because you get diminishing returns for increased power. But it's the same CPU. To go back to your original argument, you're claiming that x86 ISA is more efficient than ARM because a certain AMD chip beat certain M1/snapdragon chips at 50w. You can't draw that conclusion because the two chips may be designed to have peak efficiency at different power levels, even if the maximum power draw is the same. Likely the Snapdragon/M1 have better efficiency at 10W with reduced clock speed even if the CPU is not idling. Hence my response: it doesn't make sense to talk about performance per watt, without also specifying the workload. Not only will different workloads use different amounts of power, they will also rely on different instructions which may give different ISAs or CPUs the edge. Not to mention -- who even cares about ISA efficiency? What matters is the result for the product I can buy. If M1/snapdragon are able to match AMD on performance but beat it in battery life for my workloads, I don't care if AMD has better "performance per watt" according to your metric. | | |
| ▲ | ben-schaaf 20 hours ago | parent [-] | | > You're not taking into account dynamic clock speeds, just "idle" and "load." Most CPUs have configurable TDP, and if you give them more power they will run more cores at a higher frequency. Suppose I measured the same laptop CPU under "full load" in two different computers at full load, but one is configured for a 30w TDP and the other is configured for a 40w TDP. The first PC will be more efficient, because you get diminishing returns for increased power. But it's the same CPU. Dynamic clock speeds are exactly why you need to do this testing under full load. No you're probably not getting the same power draw on each chip, but at least you're eliminating the frequency scaling algorithms from the equation. This is why it's so hard to evaluate core efficiency (let alone what effect the ISA has). What you can do however is compare chips with wildly different performance and power characteristics. A chip that is using significantly more power to do significantly less work is less efficient than a chip using less power to do more. > To go back to your original argument, you're claiming that x86 ISA is more efficient than ARM because a certain AMD chip beat certain M1/snapdragon chips at 50w. I never claimed x86 is more efficient than ARM. I did claim the latest AMD cores are more efficient than M1 and snapdragon elite X, while still having worse battery life. > You can't draw that conclusion because the two chips may be designed to have peak efficiency at different power levels, even if the maximum power draw is the same. Likely the Snapdragon/M1 have better efficiency at 10W with reduced clock speed even if the CPU is not idling. Firstly this is pretty silly: All chips get more efficient at lower clock speed. Maximum efficiency is at at whatever the lowest clockspeed you can go, which is primarily determined by how the chip is manufactured. Which brings me to my second point: What does any of this have to do with the ISA? > Not to mention -- who even cares about ISA efficiency? What matters is the result for the product I can buy. If you don't care about ISA efficiency why are you here‽ That's what this discussion is about! If you don't care about this just leave. And to answer your question: We care about ISA efficiency because we care about the efficiency of our chips. If ARM was twice as efficient then we should be pushing to kill x86, backwards compatibility be damned. In actuality the reason ARM-based laptops have better efficiency has nothing/little to do with the ISA, so instead of asking AMD/intel to release an ARM-based chips we should be pushing them to optimize battery usage. | | |
| ▲ | fwipsy 16 hours ago | parent [-] | | You didn't understand what I said before responding. Please don't waste my time like that. |
|
|
|
| |
| ▲ | 3 days ago | parent | prev | next [-] | | [deleted] | |
| ▲ | boxed 3 days ago | parent | prev | next [-] | | He said "per watt", that's still true. You just talked about max throughput, which no one is discussing. | | |
| ▲ | dwattttt 3 days ago | parent | next [-] | | > The latest AMD under full load uses the same power as M1 and is faster, thus it has better performance per watt. He also said per watt. An AMD CPU running at full power and then stopping will use less battery than an M1 with the same task; that's comparing power efficiency. | | | |
| ▲ | ohdeargodno 3 days ago | parent | prev [-] | | It's not, because Apple purposefully lied on their marketing material. Letting a 3090 go on full blast brings it pretty much in line in perf/watt. Your 3090 will not massively thermal throttle after 30 minutes either, but the M1 Ultra will. So, yes, if you want to look good on pointless benchmarks, a M1 ultra ran for 1 minute is more efficient than a downclocked 3090. | | |
| ▲ | brookst 3 days ago | parent | next [-] | | How do you think Nvidia got Samsung’s 8nm process to be just as power efficient as TSMC’s 5nm node? | | | |
| ▲ | boxed 3 days ago | parent | prev [-] | | https://techjourneyman.com/blog/m1-ultra-vs-nvidia-rtx-3090/ Look at that updated graph which has less BS. It's never close in perf/watt. The BS part about apples graph was that they cut the graph short for the nvidia card (and bending the graph a bit at the end). The full graph still shows apple being way better per watt. | | |
|
| |
| ▲ | petrichorko 3 days ago | parent | prev [-] | | To me it's not as simple as comparing the efficiency under full load. I imagine the efficiency on x86 as some kind of log curve, which translates to higher power consumption even on lighter loads. Apple's ARM implementation tends to eat a lot less power on tasks that happen most of the time, hence greatly improving the battery life. I've tried a Ryzen 7 that had a similar efficiency to an M1 according to some tests, and that thing ran hot like crazy. Its just marketing bullshit to me now.. | | |
| ▲ | sgc 3 days ago | parent | next [-] | | The OS matters, and I would guess you were using two different OSes? I have no doubt macOS running on an m1 is more optimized than whatever you were using on the ryzen. I recently had to remove Windows completely from a few years old laptop with an 12th gen cpu and a Intel Iris / GeForce RTX 3060 Mobile combo because it was running very hot (90c+) and the fans were constantly running. Running Linux, I have no issues. I just double checked since I had not for several months, and temperature is 40c lower on my lap than it was propped up on a book for maximum airflow. Full disclaimer, I would have done this anyways, but the process was sped up because my wife was extremely annoyed with the noise my new-to-me computer was making, and it was cooking the components. I have learned to start with the OS when things are tangibly off, and only eventually come back to point the finger at my hardware. | | |
| ▲ | ashirviskas 3 days ago | parent | next [-] | | OS does matter, with Linux my M1 macbook gets kinda hot and it cannot do more than 1.5-2h of google meetings with cameras on. IIRC google meetings on macos were at least a bit more efficient. Though it has definitely been getting better in the last 1.5 years using Asahi Linux and in some areas it is a better experience than most laptops running Linux (sound, cameras, etc.). The developers even wrote a full fledged physical speaker simulator just so it could be efficiently driven over its "naive" limits. | | |
| ▲ | sgc 3 days ago | parent [-] | | That is more a "who is controlling access to hardware drivers matters" problem. I wouldn't be surprised if macOS was still a tiny bit more efficient with a level playing field, but we will never know. |
| |
| ▲ | petrichorko 3 days ago | parent | prev [-] | | Linux can definitely help with this, I had the same experience with it on Z1 (SteamOS). But even running Windows 11 in a VM on M1 does not make the machine run hot |
| |
| ▲ | ben-schaaf 3 days ago | parent | prev [-] | | If we're comparing entire systems as products you're absolutely right. That's not what this discussion is about. We're trying to compare the efficiency of the ISA. What do you think would happen if AMD replaced the x86-64 decoders with ARM64 ones, and changed nothing about how the CPU idles, how high it clocks or how fast it boosts? My guess is ARM64 is a few percent more efficient, something AMD has claimed in the past. They're now saying it would be identical, which is probably not far from the truth. The simple fact of the matter is that the ISA is only a small part of how long your battery lasts. If you're gaming or rendering or compiling it's going to matter a lot, and Apple battery life is pretty comparable in these scenarios. If you're reading, writing, browsing or watching then your cores are going to be mostly idle, so the only thing the ISA influences won't even have a current running through it. |
|
|
|
| ▲ | exmadscientist 3 days ago | parent | prev | next [-] |
| Yes, Intel/AMD cannot match Apple in efficiency. But Apple cannot beat Intel/AMD in single-thread performance. (Apple marketing works very hard to convince people otherwise, but don't fall for it.) Apple gets very, very close, but they just don't get there. (As well, you might say they get close enough for practical matters; that might be true, but it's not the question here.) That gap, however small it might be for the end user, is absolutely massive on the chip design level. x86 chips are tuned from the doping profiles of the silicon all the way through to their heatsinks to be single-thread fast. That last 1%? 2%? 5%? of performance is expensive, and is far far far past the point of diminishing returns in turns of efficiency cost paid. That last 20% of performance burns 80% of the power. Apple has chosen not to do things this way. So x86 chips are not particularly well tuned to be efficient. They never have been; it's, on some level, a cultural problem. Could they be? Of course! But then the customers who want what x86 is right now would be sad. There are a lot of customers who like the current models, from hyperscalers to gamers. But they're increasingly bad fits for modern "personal computing", a use case which Apple owns. So why not have two models? When I said "doping profiles of the silicon" above, that wasn't hyperbole, that's literally true. It is a big deal to maintain a max-performance design and a max-efficiency design. They might have the same RTL but everything else will be different. Intel at their peak could have done it (but was too hubristic to try); no one else manufacturing x86 has had the resources. (You'll note that all non-Apple ARM vendor chips are pure efficiency designs, and don't even get close to Apple or Intel/AMD. This is not an accident. They don't have the resources to really optimize for either one of these goals. It is hard to do.) Thus, the current situation: Apple has a max-efficiency design that's excellent for personal computing. Intel/AMD have aging max-performance designs that do beat Apple at absolute peak... which looks less and less like the right choice with every passing month. Will they continue on that path? Who knows! But many of their customers have historically liked this choice. And everyone else... isn't great at either. |
| |
| ▲ | mojuba 3 days ago | parent | next [-] | | > Apple has a max-efficiency design that's excellent for personal computing. Intel/AMD have aging max-performance designs that do beat Apple at absolute peak... Can you explain then, how come switching from Intel MBP to Apple Silicon MBP feels like literally everything is 3x faster, the laptop barely heats up at peak load, and you never hear the fans? Going back to my Intel MBP is like going back to stone age computing. In other words if Intel is so good, why is it... so bad? I genuinely don't understand. Keep in mind though, I'm not comparing an Intel gaming computer to a laptop, let's compare oranges to oranges. | | |
| ▲ | fxtentacle 3 days ago | parent | next [-] | | If you take a peak-performance-optimized design (the Intel CPU) and throttle it down to low power levels, it will be slower than a design optimized for low power (the Apple CPU). "let's compare oranges to oranges" That's impossible because Apple has bought up most of TSMC's 3nm production capacity. You could try to approximate by comparing Apple M4 Max against NVIDIA B300 but that'll be a very one-sided win for NVIDIA. | | |
| ▲ | wtallis 3 days ago | parent [-] | | > That's impossible because Apple has bought up most of TSMC's 3nm production capacity. You could try to approximate by comparing Apple M4 Max against NVIDIA B300 but that'll be a very one-sided win for NVIDIA. Have you not heard that Intel's Lunar Lake is made on the same TSMC 3nm process as Apple's M3? It's not at all "impossible" to make a fair and relevant comparison here. |
| |
| ▲ | VHRanger 3 days ago | parent | prev | next [-] | | > Can you explain then, how come switching from Intel MBP to Apple Silicon MBP feels like literally everything is 3x faster, the laptop barely heats up at peak load, and you never hear the fans? Going back to my Intel MBP is like going back to stone age computing. My understanding of it is that Apple Silicon's very very long instruction pipeline plays well with how the software stack in MacOS is written and compiled first and foremost. Similarly that the same applications take less RAM in MacOS than even in Linux often even because at the OS level stuff like garbage collection are better integrated. | |
| ▲ | exmadscientist 2 days ago | parent | prev | next [-] | | I did not say "Intel is so good". I said "x86 peak single-thread performance is just a hair better than Apple M-series peak". Pretty much everything else about the M-series parts is better. In particular, Apple's uncore is amazing (partly because it's a lot newer design) and you really notice that in terms of power management. | |
| ▲ | bee_rider 3 days ago | parent | prev | next [-] | | Is the Intel MacBook very old? Is it possible that your workloads are bound by something other than single-threaded compute performance? Memory? Drive speed? Is it possible that Apple did a better job tuning their OS for their hardware, than for Intel’s? | |
| ▲ | bpavuk 3 days ago | parent | prev [-] | | it all comes down to thermal budget of something as thin as MBP. |
| |
| ▲ | aurareturn 3 days ago | parent | prev | next [-] | | But Apple cannot beat Intel/AMD in single-thread performance.
AMD, Intel, Qualcomm have all reference Geekbench ST numbers. In Geekbench, Apple is significantly ahead of AMD and Intel in ST performance. So no need Apple marketing to convince us. The industry has benchmarks to do so. | |
| ▲ | steveBK123 3 days ago | parent | prev | next [-] | | > looks less and less like the right choice with every passing month It does seem like for at least the last 3-5 years it's been pretty clear that Intel x86 was optimizing for the wrong target / a shrinking market. HPC increasingly doesn't care about single core/thread performance and is increasingly GPU centric. Anything that cares about efficiency/heat (basically all consumer now - mobile, tablet, laptop, even small desktop) has gone ARM/RISC. Datacenter market is increasingly run by hyperscalers doing their own chip designs or using AMD for cost reasons. | | |
| ▲ | bee_rider 3 days ago | parent [-] | | It seems impossible that CPUs could ever catch up to GPUs, for the things that GPUs are really good at. I dunno. I sort of like all the vector extensions we’ve gotten on the CPU side as they chase that dream. But I do wonder if Intel would have been better off just monomaniacally focusing on single-threaded performance, with the expectation that their chips should double down on their strength, rather than trying to attack where Nvidia is strong. |
| |
| ▲ | whizzter 3 days ago | parent | prev | next [-] | | It's the gaming/HPC focus, sure you can achieve some stunning benchmark numbers with nice vectorized straightforward code. In the real world we have our computers running JIT'ed JS, Java or similar code taking up our cpu time, tons of small branches (mostly taken the same way and easily remembered by the branch predictor) and scattering reads/writes all over memory. Transistors not spent on larger branch prediction caches or L1 caches are badly spent, doesn't matter if the CPU can issue a few less instructions per clock to ace an benchmark if it's waiting for branch mispredictions or cache misses most of the time. There's no coincidence that the Apple teams iirc are partly the same people that built Pentium-M (that begun the Core era by delivering very good perf on mobile chips when P4 was supposed to be the flagship). | |
| ▲ | menaerus 3 days ago | parent | prev | next [-] | | > But Apple cannot beat Intel/AMD in single-thread performance It's literally one of the main Apple M chips advantage over Intel/AMD. At the time when M chip came out, it was the only chip that managed to consume ~100GB/s of MBW with just a single thread. https://web.archive.org/web/20240902200818/https://www.anand... > From a single core perspective, meaning from a single software thread, things are quite impressive for the chip, as it’s able to stress the memory fabric to up to 102GB/s. This is extremely impressive and outperforms any other design in the industry by multiple factors, we had already noted that the M1 chip was able to fully saturate its memory bandwidth with a single core and that the bottleneck had been on the DRAM itself. | | |
| ▲ | exmadscientist 2 days ago | parent [-] | | Memory bandwidth is an uncore thing, not a core thing. Apple's uncore is amazing. But that means they can feed their cores well, not that their cores are actually the absolute best performers when all the stops are pulled out. | | |
| ▲ | menaerus 2 days ago | parent [-] | | Yes, it is core and uncore, which we call a CPU, and you said "But Apple cannot beat Intel/AMD in single-thread performance." which is incorrect for the reasons above. |
|
| |
| ▲ | privatelypublic 3 days ago | parent | prev [-] | | Let's not forget- there shouldn't be anything preventing you from setting PL1 and PL2 power levels in linux or windows, AMD or Intel. Sometimes you can even set them in the Bios. Letting you limit just how much of that extra 20% power hogging perf you want. |
|
|
| ▲ | torginus 3 days ago | parent | prev | next [-] |
| There are just so many confounding factors that it's almost entirely impossible to pin down what's going on. - M-series chips have closely integrated RAM right next to the CPU, while AMD makes do with standard DDR5 far away from the CPU, which leads to a huge latency increase - I wouldn't be surprised if Apple CPUs (which have a mobile legacy) are much more efficient/faster at 'bursty' workloads - waking up, doing some work and going back to sleep - M series chips are often designed for a lower clock frequency, and power consumption increases quadratically (due to capactive charge/dischargelosses on FETs) Here's a diagram that shows this on a GPU: https://imgur.com/xcVJl1h So while it's entirely possible that AArch64 is more efficient (the decode HW is simpler most likely, and encoding efficiency seems identical): https://portal.mozz.us/gemini/arcanesciences.com/gemlog/22-0...? It's hard to tell how much that contributes to the end result. |
| |
| ▲ | magicalhippo 3 days ago | parent | next [-] | | Zen 5 also seems to have a bit of a underperforming memory subsystem, from what I can gather. Hardware Unboxed just did an interesting video[1] comparing gaming performance of 7600X Zen 4 and 9700X Zen 5 processors, and also the 9800X3D for reference. In some games the 9700X Zen 5 had a decent lead over the Zen 4, but in others it had exactly the same performance. But the 9800X3D would then have a massive lead over the 9700X. For example, in Horizon Zero Dawn benchmark, the 7600X had 182 FPS while the 9700X had 185 FPS, yet the 9800X3D had a massive 266 FPS. [1]: https://www.youtube.com/watch?v=emB-eyFwbJg | | |
| ▲ | VHRanger 3 days ago | parent [-] | | I mean, huge software with a ton of quirks like a AAA video game are arguably not a good benchmark to understand hardware. They're still good benchmarks IMO because they represent a "real workload" but to understand why the 9800X3D performs this much better you'd want some metrics on CPU cache misses in the processors tested. It's often similar to hyperthreading -- on very efficient sofware you actually want to turn SMT off sometimes because it causes too many cache evictions as two threads fight for the same L2 cache space which is efficiently utilized. So software having a huge speedup from a X3D model with a ton of cache might indicate the sofware has a bad data layout and needs the huge cache because it keeps doing RAM round trips. You'd presumably also see large speedups in this case from faster RAM on the same processor. | | |
| ▲ | magicalhippo 3 days ago | parent [-] | | > but to understand why the 9800X3D performs this much better you'd want some metrics on CPU cache misses in the processors tested. But as far as I can tell the 9600X and the 9800X3D are the same except for the 3D cache and a higher TDP. However they have similar peak extended power (~140W) and I don't see how the different TDP numbers explain the differences between 9600X and 7600X where the is sometimes ahead and other times identical, while the 9800X3D beats both massively regardless. What other factors could it be besides fewer L3 cache misses that lead to 40+% better performance of the 9800X3D? > You'd presumably also see large speedups in this case from faster RAM on the same processor. That was precisely my point. The Zen 5 seems to have a relatively slow memory path. If the M-series has a much better memory path, then the Zen 5 is at a serious disadvantage for memory-bound workloads. Consider local CPU-run LLMs as a prime example. The M-s crushes AMD there. I found the gaming benchmark interesting because it represented workloads that had workloads that just straddled the cache sizes, and thus showed how good the Zen 5 could be had it had a much better memory subsystem. I'm happy to be corrected though. |
|
| |
| ▲ | formerly_proven 3 days ago | parent | prev [-] | | > M-series chips have closely integrated RAM right next to the CPU, while AMD makes do with standard DDR5 far away from the CPU, which leads to a huge latency increase 2/3rds the speed of light must be very slow over there | | |
| ▲ | torginus 3 days ago | parent [-] | | I mean at 2GHz, and 2/3c, the signal travels about 10cm in 1 clock cycle. So it's not negligible, but I suspect it has much more to do with signal integrity and the transmission line characteristics of the data bus. I think since on mobile CPUs, the RAM sits right on top of the SoC, very likely the CPUs are designed with a low RAM latency in mind. | | |
| ▲ | christkv 3 days ago | parent | next [-] | | I think the m chips have much wider databus so bandwith is much higher as well as lower latency? | | |
| ▲ | VHRanger 3 days ago | parent [-] | | huh, it seems like the M4 pro can hit >400GB/s of RAM bandwidth whereas even a 9950x hits only 100GB/s. I'm curious how that is; in practice it "feels" like my 9950x is much more efficient at "move tons of RAM" tasks like a duckDB workload above a M4. But then again a 9950x has other advantages going on like AVX512 I guess? | | |
| ▲ | hnuser123456 3 days ago | parent [-] | | Yes, the M-series chips effectively use several "channels" of RAM (depending on the tier/size of chip) while most desktop parts, including the 9950x, are dual-channel. You get 51.2 GB/s of bandwidth per channel of DDR5-6400. You can get 8-RAM-channel motherboards and CPUs and have 400 GB/s of DDR5 too, but you pay a price for the modularity and capacity over it all being integrated and soldered. DIMMs will also have worse latency than soldered chips and have a max clock speed penalty due to signal degradation at the copper contacts. A Threadripper Pro 9955WX is $1649, a WRX90 motherboard is around $1200, and 8x16GB sticks of DDR5 RDIMMS is around $1200, $2300 for 8x32GB, $3700 for 8x64GB sticks, $6000 for 8x96GB. | | |
| ▲ | christkv 2 days ago | parent [-] | | Or you can get a strix halo 395+ that has 8 memory channels with a max of 128gb of ram. I think it does around 400 GB/s | | |
| ▲ | hnuser123456 2 days ago | parent [-] | | From what I see Strix Halo has a 256 bit memory bus, which would be like quad channel ddr5, but it's soldered so can run at 8000mt/s, which comes out to 256 GB/s. | | |
| ▲ | christkv a day ago | parent [-] | | Yeah you are right still up from the other consumer platforms |
|
|
|
|
| |
| ▲ | formerly_proven 2 days ago | parent | prev [-] | | > I mean at 2GHz, and 2/3c, the signal travels about 10cm in 1 clock cycle. So it's not negligible That's 0.5ns - if you look at end-to-end memory latencies, which are usually around 100ns for mobile systems, that actually is negligible, and M series chips do not have particularly low memory latency (they trend higher in comparison). |
|
|
|
|
| ▲ | michaelmrose 3 days ago | parent | prev | next [-] |
| RTX3090 is a desktop part optimized for maximum performance with a high-end desktop power supply. It isn't meaningful to compare its performance per watt with a laptop part. Saying it offers a certain wattage worth of the desktop part means even less because it measures essentially nothing. You would probably want to compare it to a mobile 3050 or 4050 although this still risks being a description of the different nodes more so than the actual parts. |
| |
| ▲ | KingOfCoders 3 days ago | parent [-] | | It's no comparison at all, the person who bought a 3090 in the 30xx days wanted max gaming performance, someone with an Apple laptop wants longer battery usage. It's like comparing an F150 with an Ferrari, a decision that no buyer needs to make. | | |
| ▲ | thechao 3 days ago | parent [-] | | > It's like comparing an F150 with a Ferrari, a decision that no buyer needs to make. ... maybe a Prius? Bruh. |
|
|
|
| ▲ | aredox 3 days ago | parent | prev | next [-] |
| >Intel and AMD have had plenty of years to catch up to Apple's M-architecture and they still aren't able to touch it in efficiency. Why would they spend billions to "catch up" to an ecological niche that is already occupied, when the best they could do - if the argument here is right that x86 and ARM are equivalent - is getting the same result? They would only invest this much money and time if they had some expectation of being better, but "sharing the first place" is not good enough. |
| |
| ▲ | samus 3 days ago | parent [-] | | The problem is that they are slowly losing the mobile markets, while their usual markets are not growing as they used to. AMD is less vulnerable to the issues that arise from that because they are fabless, and they could pivot entirely to GPU or non-x86 markets if they really wanted to. But Intel has fabs (very expensive in terms of R&D and capex) dedicated to products for desktop and server markets that must continue to generate revenue. | | |
| ▲ | 9rx 3 days ago | parent | next [-] | | The question remains: Why would they spend billions only to "catch up"? That means, even after the investment is made and they have a product that is just as good, there is still no compelling technical reason for the customer to buy Intel/AMD over the other alternatives that are just as good, so their only possible avenue to attract customers is to drive the price into the ground which is a losing proposition. | |
| ▲ | BoredPositron 3 days ago | parent | prev [-] | | The markets didn't really budge. Apple only grew 1% in the traditional PC market (desktop/notebook) over the last 5 years and that's despite a wave of new products. The snapdragons are below 1%... | | |
| ▲ | samus a day ago | parent [-] | | And that's fine for them since they have also have their mobile platform, which is arguably more important at this point. |
|
|
|
|
| ▲ | diddid 3 days ago | parent | prev | next [-] |
| I mean the M1 is nice but pretending that it can do in 110w what the 3090 does with 320w is Apple marketing nonsense. Like if your use case is playing games like cp2077, the 3090 will do 100fps in ultra ray tracing and an M4 Max will only do 30fps. Not to mention it’s trivial to undervolt nvidia cards and get 100% performance at 80% power. So 1/3 the power for 1/3 the performance? How is that smoking anything? |
| |
| ▲ | whatevaa 3 days ago | parent | next [-] | | Apple fans drinking apple juice, nothing new with fans, sadly. | | |
| ▲ | pjmlp 3 days ago | parent [-] | | Indeed, like talking as if Apple mattered at all in server space, or digital workstations (studio is not a replacement for people willing to buy Mac Pros, which still keep being built with Intel Xeons). |
| |
| ▲ | 3 days ago | parent | prev [-] | | [deleted] |
|
|
| ▲ | ChoGGi 3 days ago | parent | prev | next [-] |
| > The same goes for GPUs, where Apple's M1 GPU completely smoked an RTX3090 in performance-per-watt, offering 320W of RTX 3090 performance in a 110W envelope: https://images.macrumors.com/t/xuN87vnxzdp_FJWcAwqFhl4IOXs=/... I see it's measuring full system wattage with a 12900k which tended to use quite a bit of juice compared to AMD offerings. https://gamersnexus.net/u/styles/large_responsive_no_waterma... |
|
| ▲ | robotnikman 2 days ago | parent | prev | next [-] |
| > Intel and AMD have had plenty of years to catch up to Apple's M-architecture and they still aren't able to touch it in efficiency A big reason for this, at least for AMD, is because Apple buys all of TSMC's latest and greatest nodes for massive sums of money, so there is simply none left for others like AMD who are stuck a generation behind. And Intel is continually stuck trying to catch up. I would not say its due to x86 itself. |
|
| ▲ | whatagreatboy 3 days ago | parent | prev | next [-] |
| Even Jim Keller says that instruction decode is the difference, and that saves a lot of battery for ARM even if it doesn't change the core efficiency at full lot. |
|
| ▲ | KingOfCoders 3 days ago | parent | prev | next [-] |
| Why would they? They are dominated by gaming benchmarks in a way Apple isn't. For decades it was not efficiency but raw performance, 50% more power usage for 10% more performance was ok. "The same goes for GPUs, where Apple's M1 GPU completely smoked an RTX3090 in performance-per-watt" Gamers are not interested in performance-per-watt but fps-per-$. If some behavior looks strange to you, most probably you don't understand the underlying drivers. |
| |
| ▲ | goalieca 3 days ago | parent [-] | | > Gamers are not interested in performance-per-watt but fps-per-$. I game a decent amount on handheld mode for the switch. Like tens of millions of others. | | |
| ▲ | pjmlp 3 days ago | parent | next [-] | | While others run PlayStation and XBox. The demographics aren't the same, nor the games. | |
| ▲ | KingOfCoders 3 days ago | parent | prev [-] | | I game a decent amount on table top games. Like tens of millions of others. |
|
|
|
| ▲ | ohdeargodno 3 days ago | parent | prev [-] |
| [dead] |
{kind=link}
{kind=link}