| ▲ | mlmonkey 2 hours ago | |
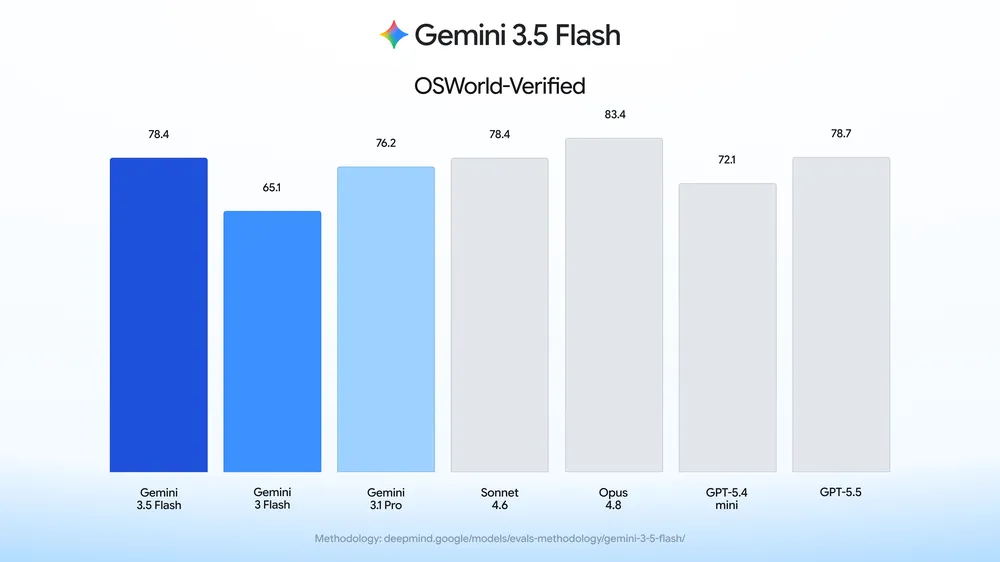
It's funny how in their own graph, https://storage.googleapis.com/gweb-uniblog-publish-prod/ima... Gemini 3.5 Flash is beat hands down by both Opus 4.8 and GPT 5.5, and yet the graph is drawn as if Gemini wins ... :-D | ||
| ▲ | mroche 2 hours ago | parent | next [-] | |
The graph has Gemini 3.5 Flash matching Sonnet 4.6, losing to Opus 4.8, and slightly behind GPT-5.5 by 0.3 points... That's not that much of a hands-down loss for Gemini for this specific workload benchmark. The methodology used: https://deepmind.google/models/evals-methodology/gemini-3-5-... Methodology: All Gemini scores are pass @1 except where otherwise noted. "Single attempt" settings allow no majority voting or parallel test-time compute. All of the results are all run with the Gemini API for the model-id gemini-3.5-flash with default sampling settings unless indicated otherwise below. To reduce variance, we average over multiple trials for smaller benchmarks. All the results for non-Gemini models are sourced from providers' self reported numbers unless otherwise mentioned below. For Claude Opus 4.7 , Sonnet 4.6, and GPT-5.5 we default to reporting maximum thinking/reasoning settings available, but when reported results are not available we use best available reasoning results. | ||
| ▲ | sheept 2 hours ago | parent | prev | next [-] | |
It highlights the Gemini models blue since that's what the article is about. The bar heights seem consistent with the values. | ||
| ▲ | gb2d_hn an hour ago | parent | prev | next [-] | |
It's honest - people who know what they are looking at will take speed and token costs into account. I don't use Gemini 3.5 for coding, but I use it as something in between a search engine and agent. | ||
| ▲ | data-ottawa an hour ago | parent | prev [-] | |
I think 3.5 flash is trying to target agentic work, like Google Search or ADK (agent development kit) use cases. It’s something cheap enough you’d put out in front of your customers, and Opus is expensive enough you wouldn’t. | ||
{kind=link}