| ▲ | terrib1e 4 hours ago |
| No mention of open weights anywhere in the piece, which is weird. Qwen, Llama, DeepSeek are months behind frontier, not years. If you're a European startup worried about getting cut off from Anthropic's API in 2027, the real question is what the open-weight frontier looks like then. Probably pretty capable. That undercuts most of the doom scenario. Also, he concedes Mythos-level capabilities will be cheap next year, then handwaves it with "you need the best AI, not good-enough AI." For most use cases, frontier minus six months is fine. |
|
| ▲ | baq 37 minutes ago | parent | next [-] |
| Open weights will remain open only if they’re significantly worse than the frontier weights. Before you challenge with benchmarks, consider the labs which release open weight models have internal testing and unpublished results. |
|
| ▲ | rTX5CMRXIfFG 3 hours ago | parent | prev | next [-] |
| Affordability of hardware that can run local LLMs is a real factor, too. Not sure when RAM prices are going down, but with everything that’s happening and can happen in the world right now, it doesn’t look like it’ll drop in the near or medium-term |
| |
| ▲ | wahnfrieden 3 hours ago | parent [-] | | No one is going to run models that are comparable to frontier locally without spending enormous sums for use at scale or in large orgs. Even with cheap RAM, you will still need a very large budget for frontier-level capability. Open models that are competitive with frontier will be used on shared hosts. | | |
| ▲ | zozbot234 an hour ago | parent | next [-] | | > No one is going to run models that are comparable to frontier locally without spending enormous sums for use at scale You can always run these models cheaper locally if you're willing to compromise on total throughput and speed of inference. For most end-user or small-scale business needs, you don't really need a lot of either. | | |
| ▲ | 9dev an hour ago | parent [-] | | It would be awful if running models locally became the primary way of using LLMs. On dedicated servers sharing GPUs across requests, energy usage and environmental impact is way lower overall than if everyone and their mother suddenly needs beefy GPUs. It’s the equivalent of everyone commuting alone in their own car instead of a train picking up hundreds at once. | | |
| ▲ | zozbot234 38 minutes ago | parent [-] | | You can batch requests when running locally too, if you're using a model with low-enough requirements for KV-cache; essentially targeting the same resource efficiencies that the big providers rely on. This is useful since it gives you more compute throughput "for free" during decode, even when running on very limited hardware. |
|
| |
| ▲ | jorvi 3 hours ago | parent | prev [-] | | Models have been capped out on training and (active) parameters a while ago, its tooling / harness that is making the big jumps in performance happen. And then you have things like DeepSeek with a pretty small KV cache. And with the extreme chip shortages for the next two years, there's little appetite for even bigger models anyway. Barring a breakthrough in scaling, the only direction the models can really go is smaller. Which will inevitably mean better performing local models for same chip budget. |
|
|
|
| ▲ | pu_pe an hour ago | parent | prev | next [-] |
| There are two problems with that scenario: 1. Your European startup will be competing with others using a much better frontier model. In a scenario where you already have other major disadvantages (access to capital, labor), you might be outcompeted 2. Open models have been keeping pace very nicely, but they rely on distillation of frontier models. If the race gets really tight, this could be affected so that the time gap grows larger (ie, it's very unlikely anyone but Anthropic is distilling from Mythos at the moment) |
|
| ▲ | BrtByte 3 hours ago | parent | prev | next [-] |
| Open weights undercut the absolute cutoff scenario. They don't fully solve the question of who gets the best model first, who gets enough tokens to use it heavily, and who gets to integrate it into sensitive workflows without waiting for permission |
|
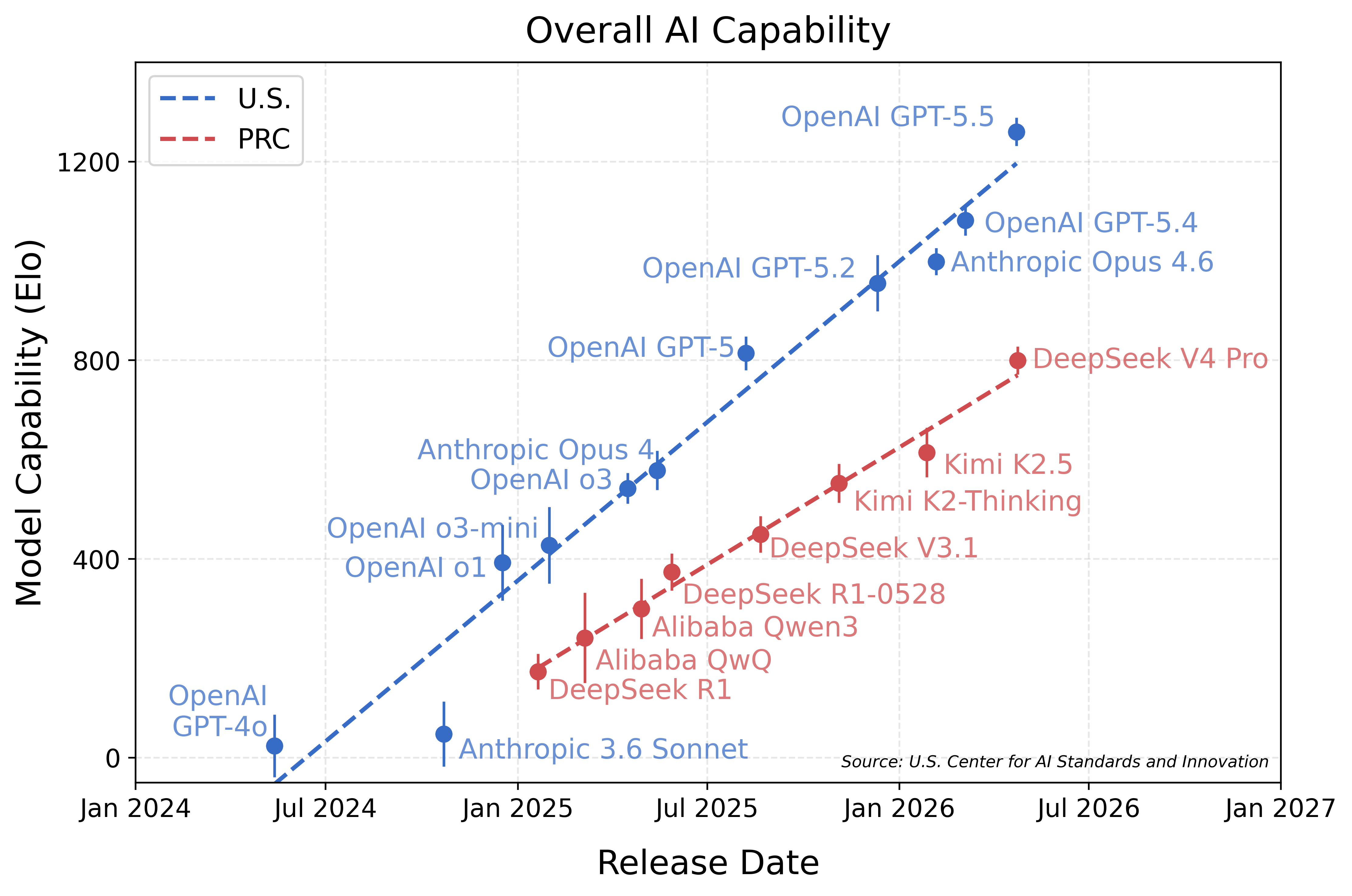
| ▲ | cubefox an hour ago | parent | prev | next [-] |
| Someone recently made a graph showing that the gap between US American frontier LLMs and Chinese open weight LLMs (including DeepSeek v4) is widening. Unfortunately I can't find it anymore. Update: GPT-5.5 found it. Article:
https://www.nist.gov/news-events/news/2026/05/caisi-evaluati... Graph: https://www.nist.gov/sites/default/files/images/2026/05/01/1... |
| |
| ▲ | lugu 3 minutes ago | parent [-] | | Someone is an official website of the united states gouvernement. I would prefer another source. |
|
|
| ▲ | wahnfrieden 3 hours ago | parent | prev | next [-] |
| Llama is not months behind GPT 5.5 Pro. I don't think Qwen or DeepSeek are either. edit: I'm specifically referring to the "5.5 Pro" model, not regular 5.5 with Pro tier subscription. Claude has no model available that's comparable to 5.5 Pro either. |
| |
| ▲ | vasachi 3 hours ago | parent [-] | | I’ve used DeepSeek 4 Pro through Claude. It’s fine. Plans are similar to what sonnet/opus make. Same massage-the-plan -> massage-the-code loop. Maybe the code is a bit worse, but that’s the “months behind” thing. The thing is, vast majority of code tasks aren’t a venture into the unknown. We as an industry for the most part build CRUD interfaces and dashboards. That can be achieved, with supervision, with frontier open-weights models quite well. | | |
| ▲ | fwipsy 3 hours ago | parent [-] | | I think maybe you are both right. Perhaps AI coding assistants just don't need to be all that smart in many cases, so open weights models are fine. At the same time, frontier models are advancing in other domains, like mathematics, where raw intelligence is a more important factor. | | |
| ▲ | vasachi 3 hours ago | parent [-] | | I can’t compare raw intelligence of these models, and I certainly can’t say anything about their advances in mathematics (without repeating press releases). But, erm, does it really matter? It’s not like some engineer somewhere will vibe-calculate how much weight a bridge can hold. Well, yes, someone probably will do that. But I’m pretty sure there will be consequences for the engineer errors in this vibe-calculations. |
|
|
|
|
| ▲ | sholladay 3 hours ago | parent | prev [-] |
| Open models are pretty good at this point but the problem is that they are limited by the tooling and infrastructure that surrounds them. For example, the last time I tried to set up web search with an open model, the experience was pretty bad. |
{kind=link}