| ▲ | greggh 7 hours ago | |
The only thing I question is the use of Maverick in their comparison charts. That's like comparing a pile of rocks to an LLM. | ||
| ▲ | jychang 3 hours ago | parent | next [-] | |
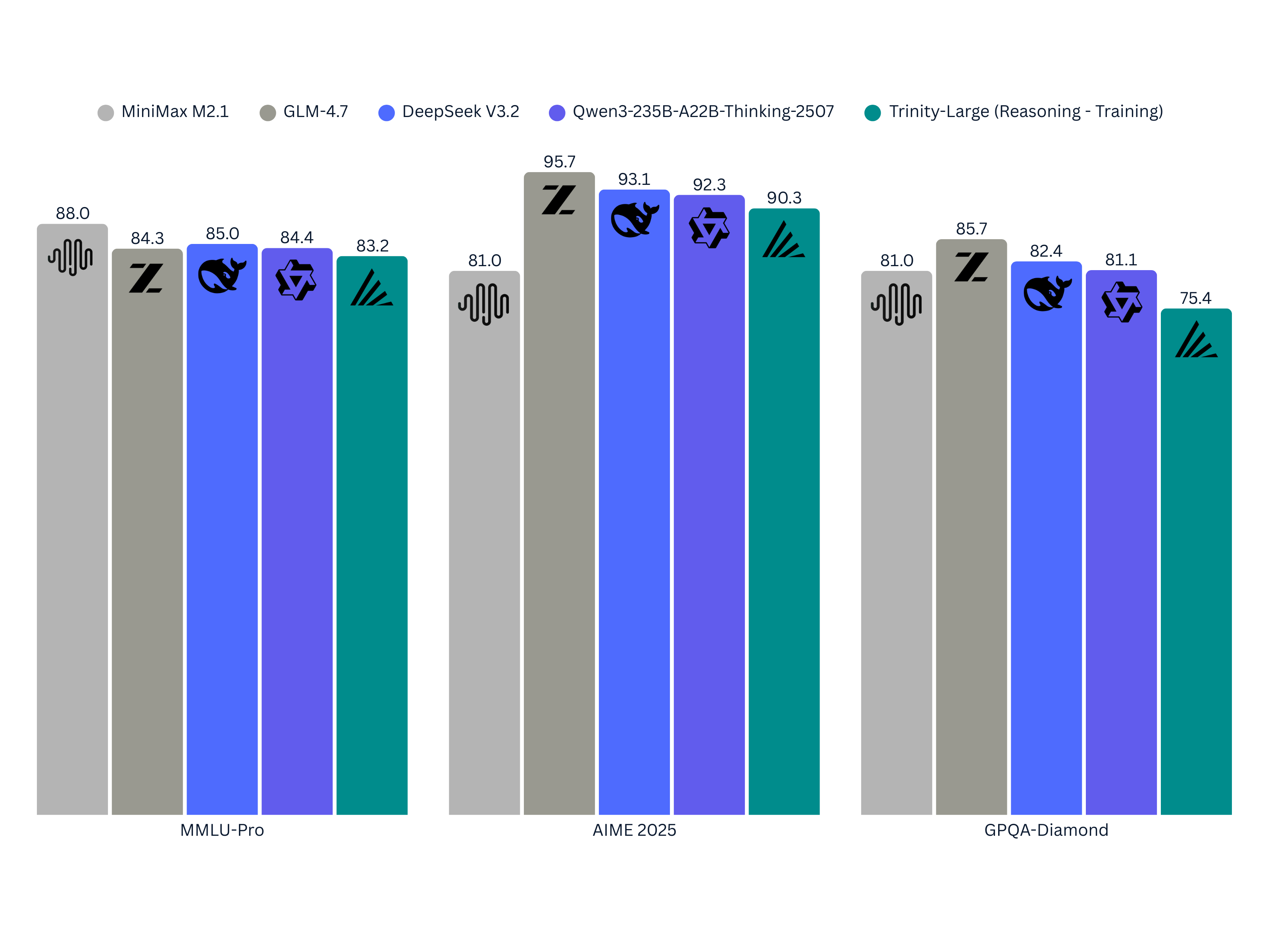
It's because they're doing 4 of 256 sparsity, which was a bad decision caused by financial limitations. Training cost (FLOPs) = 6 * active params * total tokens. By keeping the MoE experts param count low, it reduces total training costs. I don't think this was a good move. They should have just trained way past chinchilla like the other major labs, and keep sparsity above 2%. Even Kimi K2 is above 2%. GLM is at 5%, which makes it very expensive (and high performing) for its small size. Arcee went the other way. They trained a massive 400b model (bigger than GLM-4.5/4.6/4.7, bigger than Qwen3 235b A23b), but only have 17b active params, which is smaller than Qwen and GLM. It's also only trained on 17T tokens, vs 20-30T+ tokens for the other models. It's just undertrained and undersized (in terms of active parameters), and they got much worse performance than those models: https://45777467.fs1.hubspotusercontent-na1.net/hubfs/457774... It's not a bad showing considering the limitations they were working with, but yeah they definitely need double the active experts (8 out of 256 instead of 4 out of 256) to be competitive. That would roughly double the compute cost for them, though. Their market strategy right now is to have less active params so it's cheaper for inference, more total params so it's smarter for the amount of active params they have, but not too big to fit into a H200 cluster. I... guess this is a valid niche strategy? The target audience is basically "people who don't need all the intelligence of GLM/Qwen/Deepseek, but want to serve more customers on the H200 cluster they already have sitting around". It's a valid niche, but a pretty small one. | ||
| ▲ | eldenring 5 hours ago | parent | prev [-] | |
There aren't too many base models out there to compare against. | ||
{kind=link}