| ▲ | martinald a day ago | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
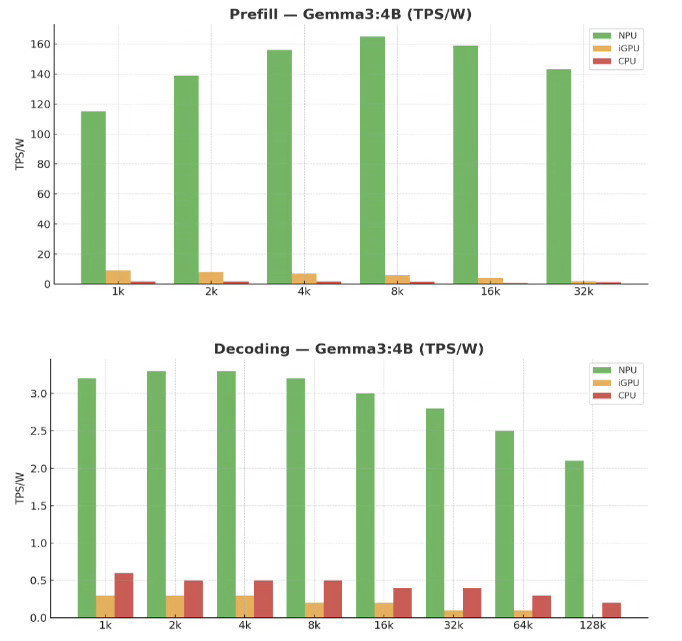
The problem is essentially memory bandiwdth afiak. Simplifying a lot in my reply, but most NPUs (all?) do not have faster memory bandwidth than the GPU. They were originally designed when ML models were megabytes not gigabytes. They have a small amount of very fast SRAM (4MB I want to say?). LLM models _do not_ fit into 4MB of SRAM :). And LLM inference is heavily memory bandwidth bound (reading input tokens isn't though - so it _could_ be useful for this in theory, but usually on device prompts are very short). So if you are memory bandwidth bound anyway and the NPU doesn't provide any speedup on that front, it's going to be no faster. But has loads of other gotchas so no real "SDK" format for them. Note the idea isn't bad per se, it has real efficiencies when you do start getting compute bound (eg doing multiple parallel batches of inference at once), this is basically what TPUs do (but with far higher memory bandwidth). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ▲ | zozbot234 a day ago | parent [-] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
NPUs are still useful for LLM pre-processing and other compute-bound tasks. They will waste memory bandwidth during LLM generation phase (even in the best-case scenario where they aren't physically bottlenecked on bandwidth to begin with, compared to the iGPU) since they generally have to read padded/dequantized data from main memory as they compute directly on that, as opposed to being able to unpack it in local registers like iGPUs can. > usually on device prompts are very short Sure, but that might change with better NPU support, making time-to-first-token quicker with larger prompts. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
{kind=link}