| ▲ | kqr 6 days ago | |||||||||||||||||||
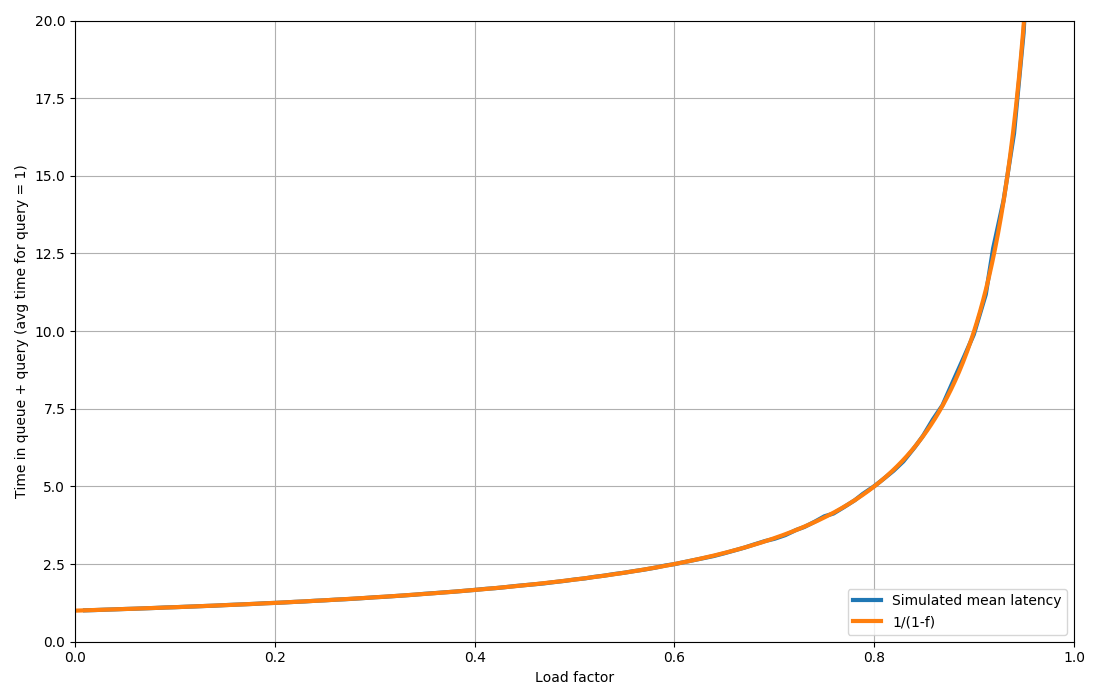
It might be a lie, but it surely is a practical one. In my brief foray into site reliability engineering I used CPU utilisation (of CPU-bofund tasks) with queueing theory to choose how to scale servers before big events. The %CPU suggestions ran contrary to (and were much more conservative than) the "old wisdom" that would otherwise have been used. It worked out great at much lower cost than otherwise. What I'm trying to say is you shouldn't be afraid of using semi-crappy indicators just because they're semi-crappy. If it's the best you got it might be good enough anyway. In the case of CPU utilisation, though, the number in production shouldn't go above 40 % for many reasons. At 40 % there's usually still a little headroom. The mistake of the author was not using fundamentals of queueing theory to avoid high utilisation! | ||||||||||||||||||||
| ▲ | therealdrag0 6 days ago | parent | next [-] | |||||||||||||||||||
> semi-crappy indicator … good enough. Agree. Another example of this is for metrics as percentiles per host that you have to average, vs histograms per host that get percentile calculated at aggregation time among hosts. Sure an avg/max of a percentile is technically not a percentile, but in practice switching between one or the other hasn’t affected my operations at all. Yet I know some people are adamant about mathematical correctness as if that translates to operations. | ||||||||||||||||||||
| ||||||||||||||||||||
| ▲ | mayama 6 days ago | parent | prev | next [-] | |||||||||||||||||||
Combination of CPU% and loadavg would generally tell how system is doing. I had systems where loadavg is high, waiting on network/io, but little cpu%. Tracing high load is not always straightforward as cpu% though, you have to go through io%, net%, syscalls etc. | ||||||||||||||||||||
| ▲ | saagarjha 6 days ago | parent | prev | next [-] | |||||||||||||||||||
40% seems quite lightly utilized tbh | ||||||||||||||||||||
| ||||||||||||||||||||
| ▲ | zekrioca 6 days ago | parent | prev [-] | |||||||||||||||||||
I noticed exactly the same thing. The author is saying something that has been repeatedly written in queueing theory books for decades, still they are noticing this only now. | ||||||||||||||||||||
{kind=link}